by Joseph Brady, Director of Business Development at Treehouse Software, Inc. and Dan Vimont, Director of Innovation at Treehouse Software, Inc.
We are beginning to see a pleasant and welcomed trend with Treehouse customers who are looking to modernize their valuable mainframe legacy data on the Cloud—they are including their data science teams in the important planning phase of architecting new Cloud environments and targets. This is especially vital for customers who want to incorporate advanced analytics and ML/AI in their strategic data usage plans on the Cloud. Who can contribute better understandings of ultimate data usage than your resident data scientists?
We have heard from many of these data scientists that a primary item on their “wish lists” is for a fully managed, AI powered, massively parallel processing (MPP) architecture to extract maximum value and insights. They specifically mention Amazon Redshift as the Cloud data warehouse (which is much more than a data warehouse) of choice for driving digitization across the enterprise, as well as help personalizing customer experiences. Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the highest performance at any scale. To this desire/question, we can answer with a resounding, “Yes, Treehouse Software has got you covered with Redshift connectivity!”.
The Treehouse Software solution…
Enterprise customers have come to Treehouse Software, because we bring not only proven mainframe data replication tools, but deep subject matter expertise in mainframe technologies, as well as the know-how to target relevant AWS offerings, such as Redshift, S3 (including S3 Express One Zone – see our recent blog on S3 Express One Zone), etc.
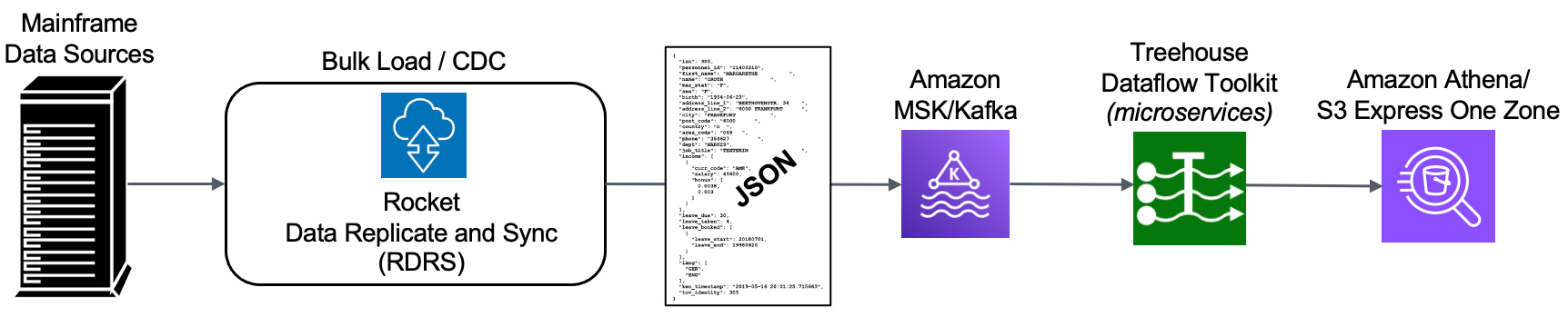
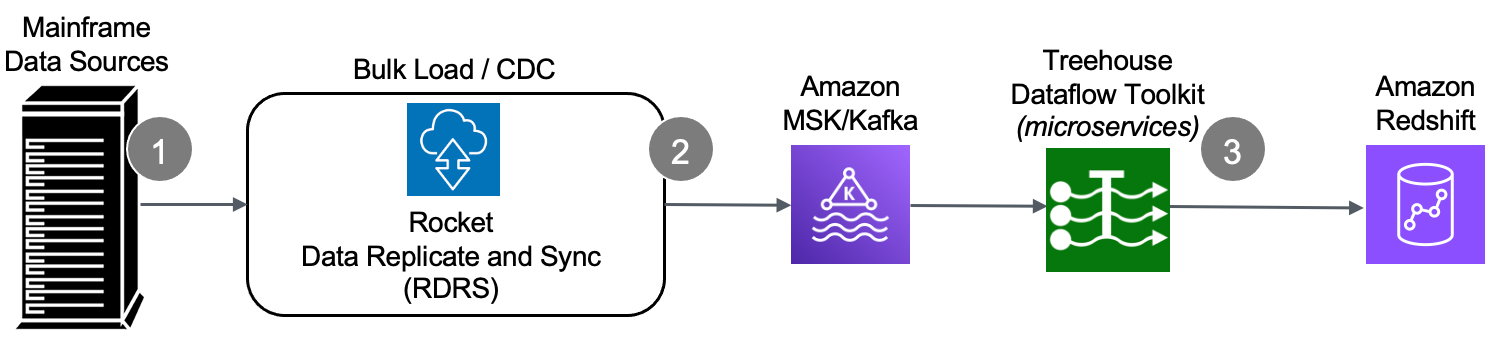
The Rocket Data Replicate and Sync (RDRS) solution allows customers’ legacy mainframe environment to operate normally while replicating data on AWS. The technology focuses on changed data capture (CDC) when transferring information between mainframe data sources and Cloud-based databases and applications. Through an innovative set of technologies, changes occurring in any mainframe datastore are tracked and captured, and ultimately published to Redshift.
How does it work?
We start at the source – the mainframe – where an agent (with a very small footprint) extracts data (in the context of either bulk-load or CDC processing).
The raw data is securely passed from the mainframe to RDRS, which speedily transforms mainframe-formatted data into Unicode/JSON and publishes the results to a Kafka topic.
Our efficient, autoscaling microservices take it from there. Treehouse Dataflow Toolkit functions consume the data from Kafka and land it in S3 buckets, where Treehouse’s proprietary crawler technology is used to automatically prepare landing tables, views, and additional infrastructure in Redshift. Thenthe mainframe data is loaded into Redshift (all the while adhering to AWS’ recommended “best practices” for massive data loading, thus assuring shortest and surest loads). The inherent reliability and scalability of the entire pipeline infrastructure assure near-real-time synchronization between mainframe sources and Redshift target tables.
Redshift tables and views: something for everybody
Within this framework, the Redshift staging tables (often referred to as “delta tables”) are constantly accruing historical data, ideally suited for data scientists looking to do trend analysis, predictive analytics, ML, and AI work. For business analysts and others who prefer structured data representations of potentially complex hierarchical data, the Treehouse framework also automatically provides structured user-views, providing the look and feel of a SQL database.
…as innovations move faster along the timeline, keep your options open!
Publishing both bulk-load and CDC data to a reliable and scalable framework like Kafka allows you to maintain a broad array of options to ultimately feed your legacy data to any number of JSON-friendly ETL tools, target datastores, and data analytics packages (some of which may not even have been invented yet!). In addition to Redshift, the Treehouse Dataflow Toolkit also currently targets Snowflake, Amazon DynamoDB, and Amazon Athena/S3.
Video – Introduction to Data Warehousing on AWS with Amazon Redshift…
Contact Treehouse Software today to discuss your project, or to schedule a demo of our Mainframe-to-AWS real-time and bi-directional data replication solution.
by Joseph Brady, Director of Business Development and Cloud Alliance Leader at Treehouse Software, Inc.
Treehouse Software specializes in helping enterprise customers with Mainframe-to-Cloud, Multi-Cloud, and Hybrid Cloud data modernization projects. Many times, our customers not only discuss strategies for replicating their mainframe data, but also their plans for what they want to do with that data on the Cloud side. This makes it important to our team to stay current on the latest Cloud offerings that can benefit our customers’ enterprise modernization planning. Consequently, a very exciting announcement caught our attention during the 2023 AWS re:Invent conference—the general availability of a new type of S3 storage service referred to as Amazon S3 Express One Zone Storage Class.
For those unfamiliar, Amazon S3 (“simple storage service”) is the basic file storage service of AWS, and as such it forms a foundational pillar of the entire AWS world. Amazon S3 Express One Zone is a new type of S3 bucket called a “directory bucket”, which is purpose-built to deliver consistent, single-digit millisecond data access for an enterprise’s most frequently used data and latency-sensitive applications. The new S3 directory buckets allow customers to store data in a single Availability Zone (AZ) that they specifically select, as opposed to the default of three AZs for standard S3. This eliminates the latency associated with spreading data across multiple AZs, providing applications with lower-latency storage. S3 directory buckets also follow a different request scaling model compared to traditional buckets, and their authentication is based on sessions rather than on a per-request basis. Bottom line… reduction in compute time = greater cost reduction.
S3 Express One Zone is ideally suited for services such as Amazon SageMaker Model Training, Amazon Athena, Amazon EMR, and AWS Glue Data Catalog to accelerate Machine Learning (ML) and interactive analytics workloads. With S3 Express One Zone, storage automatically scales up or down based on consumption and need, and customers no longer need to manage multiple storage systems for low-latency workloads.
So, why is S3 Express One Zone important to Treehouse mainframe modernization customers?
Amazon S3 Express One Zone just made the Amazon S3 targeting in the Treehouse Dataflow Toolkit (TDT) potentially much more potent and valuable to our enterprise mainframe customers. When an enterprise uses TDT to land their mission critical data in Express One Zone flavored Athena/S3 buckets, it becomes more directly accessible and manipulable by the various AWS ML and AI tools. In short, if customers choose, Express One Zone Athena/S3 becomes an intermediate data store for big data processing workloads and advanced analytics.
So, when we are asked, “What should Treehouse Software be doing to respond to the burgeoning interest in ML, Generative AI, etc.?”, the answer is — We are doing exactly what we need to be doing. AI and ML frameworks are the newest incentive for people to use RDRS (Rocket Data Replicate and Sync — formerly called tcVISION) and TDT from Treehouse Software to replicate their mainframe data on advanced data analytics frameworks, or possibly into super-charged S3 Express One Zone buckets.
Video – Deep Dive Introduction to Amazon S3 Express One Zone Storage Class:
Contact Treehouse Software today to discuss your project, or to schedule a demo of our Mainframe-to-AWS real-time and bi-directional data replication solution.
by Joseph Brady, Director of Business Development and Cloud Alliance Leader at Treehouse Software, Inc.
I have recently been taking some classes in preparation for an AWS certification. In some of these classes, an example scenario has been used that speaks to an issue I’ve often heard mentioned by Treehouse mainframe customers–that of “Regional Data Sovereignty”. For example, a customer might have government compliance requirements that financial information in Frankfurt cannot leave Germany, and many other countries have similar restrictions and regulatory controls in place.
Fortunately, Regional Data Sovereignty is a critical part of the design of AWS Global Infrastructure. Within this infrastructure, there are AWS Regions which address data that is subject to local laws and statutes of the country in which a Region is located. With the understanding that the customer’s data and application live and runs in various geographical Regions, there are four business factors a customer should consider when choosing a Region:
Compliance. Before any other factors, customers must first look at their regional compliance requirements to determine if data must live within certain geographical boundaries.
Proximity. How close the enterprise is to its customer base is another major factor because of possible latency issues between countries. Locating a Region closest to the customer base is generally the best choice.
Feature availability. Sometimes the closest Region may not have all the AWS features a business needs. Every year thousands of new features and products specifically to answer customer requests and needs are released by AWS. But sometimes those new services require new physical hardware that AWS has to build, so the service might be available one Region at a time.
Pricing. Even when the hardware is equal from one Region to the next, some locations are more expensive in which to operate. For example, the same workload in Sao Paulo could be significantly more expensive than if it is run out of Oregon in the United States.
Additionally, events such as natural disasters, can happen to cause customers to lose connection to a data center, so a High Availability (HA) cutover plan should also be considered. The customer can run a second data center, but real estate prices alone could restrict that when considering all the duplicate expense of hardware, employees, electricity, heating and cooling, and security. Most businesses simply end up just storing backups somewhere, and then hope for the disaster to never come. And “hope” is not a good business plan. I recently covered how Treehouse Software can help provide an HA framework for mainframe customers in another blog.
Let’s take a look at the AWS Global Infrastructure and how its Regions are distributed worldwide…
AWS Regions are built to be closest to the highest business traffic demands, such as in Paris, Tokyo, Sao Paulo, Dublin, and Ohio. Inside each Region, there are multiple data centers that have all the compute, storage, and other services customers need to run their applications. By utilizing AWS Regions for high availability of its business services, customers can be assured of minimal downtime of operations. Regions can be connected to each other through the high-speed AWS Direct Connect, which bypasses the public Internet, and the customer’s business decision maker chooses which Region they want to use. Each Region is isolated from every other Region in the sense that absolutely no data goes in or out of the customer’s environment in that Region without explicit permission for that data to be moved. These elements should be part of all critical strategic and security conversations when planning global distribution and availability of an enterprise’s data on AWS.
Video – AWS Global Infrastructure explained…
Contact Treehouse Software today to discuss your project, or to schedule a demo of our Mainframe-to-AWS real-time and bi-directional data replication solution.
by Dan Vimont, Cloud Solutions Architect at Treehouse Software, Inc.
Treehouse Software customers are using tcVISION to enable mission-critical mainframe-to-AWS data replication pipelines. Some of these production pipelines are providing vital near-real-time synchronization between source and target, and thus can’t afford any significant downtime in the event of failure. So it’s only natural that a number of our customers have been asking for advice in setting up a high availability configuration for their tcVISION components that run on AWS EC2 instances. The High Availability Framework discussed here provides for a Failover EC2 instance to automatically pick up tcVISION processing should the Primary instance (running in another Availability Zone) go down.
The Core Components: Primary Instance & Failover Instance
The core components of a tcVISION high availability framework consist of two EC2 instances running in different Availability Zones: a Primary EC2 instance and a Failover EC2 instance. Both identically-configured EC2 instances are attached to a shared working-storage file system (either an EFS or FSx volume), which allows the Failover instance to seamlessly and quickly pick up tcVISION processing should the Primary instance suddenly become unavailable.
Use a Step Function to Automate the Failover Process
In the event of failure of the Primary instance, the recommended framework calls for automatic triggering of a Step Function for reliable failover processing, with steps that include the following:
verify that the Primary instance is unavailable (The tcVISION service cannot be active on both instances simultaneously, so this verification is vital.)
redirect all network traffic from the Primary instance to the Failover instance (via Route 53)
start tcVISION processing on the Failover instance
When Ready, Use a Step Function to Automate the Restoration Process
After operations personnel have completed recovery of the Primary EC2 instance, another Step Function may be manually triggered to reliably transfer tcVISION processing back to the Primary instance.
Many More Details are Available Upon Request to Treehouse Customers
by Joseph Brady, Director of Business Development and Cloud Alliance Leader at Treehouse Software
Careful planning must occur for a Mainframe-to-Cloud data modernization project, including how a customer’s desired Cloud environment will look. This blog serves as a general guide for organizations planning to replicate their mainframe data on Cloud platforms using Treehouse Software‘s tcVISION.
A successful move to the Cloud requires a number of post-migration considerations and solutions in order to modernize an application on the Cloud. Some examples of these considerations and solutions include:
Personnel Resource Considerations
Staffing for Mainframe-to-Cloud data replication projects depends on the scale and requirements of your replication project (e.g., bi-directional data replication projects will require more staffing).
Most customers deploy a data replication product with Windows and Linux knowledgeable staff at varying levels of seniority. For the architecture and setup tasks, we recommend senior technical staff to deal with complex requirements around the mainframe, Cloud architecture, networking, security, complex data requirements, and high availability. Less senior staff are effective for the more repeatable deployment tasks such as mapping new database/file deployments. Business staff and system staff are rarely required but can be necessary for more complex deployment tasks. For example, bi-directional replication requires matching keys on both platforms and their input might be required. Other activities would be PII consideration, specifics of data transformation and data verification requirements.
An example of staffing for a very large deployment might be one very part-time project manager, a part-time mainframe DBA/systems programmer, 1-2 staff to setup and deployment the environment and an additional 1-2 staff to manage the existing replication processes.
Environment Considerations
As part of the architecture planning, your team needs to decide how many tiers of deployment are needed for your replication project. Much like with applications, you may want a Dev, QA, and Prod tier. For each of these tiers, you will need to decide the level of separation. For example, you might combine Dev and QA, but not Prod. Many customers will keep production as a distinct environment. Each environment will have its own set of resources, including mainframe managers (possibly on separate LPARs), Could VMs (e.g., EC2) for replication processing, and for managed Cloud RDBMSs (such as AWS RDS).
After the required QA testing, changes are deployed to the production environment. Object promotion test procedures should be detailed and documented, allowing for less experience personnel to work in some testing tasks. Adherence to details, processes, and extended testing is most import when deploying bi-directional replication, due to the high impact of errors and difficult remediation.
Rollout Planning
A data replication product is typically deployed using Agile methods with sprints. This allows for incrementally realized business value. The first phase is typically a planning/architecture phase during which the technical architecture and deployment process are defined. Files for replication are deployed in groups during sprint planning. Initial sprint deployments might be low value file replications to shield the business from any interruptions due to process issues. Once the team is satisfied that the process is effective, replication is working correctly, and data is verified on the source and targets, wide scale deployments can start. The number of files to deploy in a sprint will depend on the customer’s requirements. An example would be to deploy 20 mainframe files per 2–3-week sprint. Technical personnel and business users need to work together to determine which files and deployment order will have the greatest business benefit.
Security
For security, both on-premises and to the major Cloud environments, there are several considerations:
Data will be replicated between a source and target. The data security for PII data must be considered. In addition, rules such as HIPPA, FIPS, etc. will govern specific security requirements.
The path of the data must be considered, whether it is a private path, or if the data transverses the internet. For example, when going from on-premises to the Cloud the major Cloud providers have a VPN option which encrypts data going over the internet. More secure options are also available, such as AWS Direct Connect and Azure ExpressRoute. With these options, the on-premises network is connected directly to the Cloud provider edge location via a telecom provider, and the data goes over a private route rather than the internet.
Additionally, Cloud services such as S3, Azure Blob Storage, and GCP buckets default to route service connections over the internet. Creating a private end point (e.g., AWS PrivateLink) allows for a private network connection within the Cloud provider’s network. Private connections that do not traverse the Internet provide better security and privacy.
Protecting data at rest is important for both the source and target environments. The modern Z/OS mainframe has advanced pervasive and encryption capabilities: https://www.redbooks.ibm.com/redbooks/pdfs/sg248410.pdf. The major Cloud providers all provide extensive at-rest encryption capabilities. Turning on encryption for Cloud Storage and databases is often just a parameter setting and the Cloud provider takes care of the encryption, keys, and certificates automatically.
Protecting data in transit is equally important. There are often multiple transit points to encrypt and protect. First, is the transit from the mainframe to on-premises to the Cloud VM instance. A mainframe data replication product should provide protection employing TLS 1.2 to utilize keys and certificates on both the mainframe and Cloud. Second is from the Cloud VM to the Cloud target database or service. Encryption may be less important since often these services are in a private environment. However, encryption can be achieved as required.
High Availability
During CDC processing, high availability must be maintained in the Cloud environment. The data replication product should keep track of processing position. The first can be a Restart file, which keeps track of mainframe log position, target processing position, and uncommitted transactions. The second can be a container stored on Linux or Windows to store committed unprocessed transactions. Both need to be on highly available storage with a preference for storage across Availability Zones (AZs), such as Elastic File System (Amazon EFS) or Windows File Server (FSx).
The Amazon EC2 instance (or other Cloud instance) can be part of an Auto Scaling Group spread across AZs with minimum and maximum of one Amazon EC2 instance.
Upon failure, the replacement Amazon EC2 instance of the replication product’s administrator function is launched and communicates its IP address to the product’s mainframe administrator function. The mainframe then starts communication with the replacement Amazon EC2 instance.
Once the Amazon EC2 instance is restarted, it continues processing at the next logical restart point, using a combination of the LUW and Restart files.
For production workloads, Treehouse Software recommends turning on Multi-AZ target and metadata databases.
Scalable Storage
With scalable storage provided on most Cloud platforms, the customer pays only for what is used. The data replication product should require file-based storage for its files that can grow in size if target processing stops for an unexpected reason. For example, Amazon EFS, and Amazon FSx provide a serverless elastic file system that lets the customer share file data without provisioning or managing storage.
Analytics
All top Cloud platform providers give customers the broadest and deepest portfolio of purpose-built analytics services optimized for all unique analytics use cases. Cloud analytics services allow customers to analyze data on demand, and helps streamline the business intelligence process of gathering, integrating, analyzing, and presenting insights to enhance business decision making.
A data replication product should replicate data to several data sources that can easily be captured by various Cloud based analytics services. For example, mainframe database data can be replicated to the various Cloud ‘buckets’ in JSON, CSV, or AVRO format, which allows for consumption by the various Cloud analytic services. Bucket types include AWS S3, Azure BLOB Data, Azure Data Lake Storage, and GCP Cloud storage. Several other Cloud analytics type services also support targets including Kafka, Elasticsearch, HADOOP, and AWS Kinesis.
Kafka has become a common target and can serve as a central data repository. Most customers target Kafka using JSON formatted replicated mainframe data. Kafka can be installed on-premises, or using a managed Kafka service, such as the Confluent Cloud, AWS Managed Kafka, or the Azure Event Hub.
Monitoring
Monitoring is a critical part of any data replication process. There are several levels of monitoring at various points in a data replication project. For example, each node of the replication including the mainframe, network communication, Cloud VM instances (such as EC2) and the target Cloud database service all can require a level of monitoring. The monitoring process will also be different in development or QA vs. a full production deployment.
A data replication product should also have its own monitoring features. One important area to measure is performance and it is important to determine where any performance bottleneck is located. Sometimes it could be the mainframe process, the network, the transformation computation process, or the target database. A performance monitor helps to detect where the bottleneck is occurring and then the customer can drill down into specifics. For example, if the bottleneck is the input data, areas to examine are the mainframe replication product component performance, or the network connection. The next step is to monitor the area where the bottleneck is occurring using the data replication product’s statistics, mainframe monitoring tools, or Cloud monitoring such as AWS CloudWatch.
A data replication product should also allow the customer to monitor processing functions during the replication process. The data replication product should also have extensive logs and traces that allow for detailed monitoring of the data replication process and produce detailed replication statistics that include a numeric breakdown of processing statistics by table, type of operation (insert, update delete), and where these operations occurred (mainframe, or target database).
CloudWatch collects monitoring and operational data in the form of logs, metrics, and events, providing customers with a unified view of AWS resources, applications, and services that run on AWS, and on-premises servers. You can use CloudWatch to set high resolution alarms, visualize logs and metrics side by side, take automated actions, troubleshoot issues, discover insights to optimize your applications, and ensure they are running smoothly.
Some customers are satisfied with a basic monitoring that polls every five minutes, while others need more detailed monitoring and can choose polls that occur every minute.
CloudWatch allows customers to record metrics for EC2 and other Amazon Cloud Services and display them in a graph on a monitoring dashboard. This provides visual notifications of what is going on, such as CPU per server, query time, number of transactions, and network usage.
Given the dynamic nature of AWS resources, proactive measures including the dynamic re-sizing of infrastructure resources can be automatically initiated. Amazon CloudWatch alarms can be sent to the customer, such as a warning that CPU usage is too high, and as a result, an auto scale trigger can be set up to launch another EC2 instance to address the load. Additionally, customers can set alarms to recover, reboot, or shut down EC2 instances if something out of the ordinary happens.
Disaster Recovery
IT disasters such as data center failures, or cyber attacks can not only disrupt business, but also cause data loss, and impact revenue. Most Cloud platforms offer disaster recovery solutions that minimize downtime and data loss by providing extremely fast recovery of physical, virtual, and Cloud-based servers.
A disaster recovery solution must continuously replicate machines (including operating system, system state configuration, databases, applications, and files) into a low-cost staging area in a target Cloud account and preferred region.
Unlike snapshot-based solutions that update target locations at distinct, infrequent intervals, a Cloud based disaster recovery solution should provide continuous and asynchronous replication.
Consult with your Cloud platform provider to make sure you are adhering to their respective best practices.
Many organizations lack the internal resources to support AI and machine learning initiatives, but fortunately the leading Cloud platforms offer broad sets of machine learning services that put machine learning in the hands of every developer and data scientist. For example, AWS offers SageMaker, GCP has AI Platform, and Microsoft Azure provides Azure AI.
Applications that are good candidates for AI or ML are those that need to determine and assign meaning to patterns (e.g., systems used in factories that govern product quality using image recognition and automation, or fraud detection programs in financial organizations that examine transaction data and patterns).
The list goes on…
Treehouse Software and our Cloud platform and migration partners can advise and assist customers in designing their roadmaps into the future, taking advantage of the most advanced technologies in the world.
Successful customer goals are top priority for all of us, and we can continue to work with our customers on a consulting basis even after they are in production.
Of course, each project will have unique environments, goals, and desired use cases. It is important that specific use cases are determined and documented prior to the start of a project and a tcVISION POC. This planning will allow the Treehouse Software team and the customer develop a more accurate project timeline, have the required resources available, and realize a successful project.
Your Mainframe-to-Cloud Data Migration Partner…
Treehouse Software is a global technology company and Technology Partner with AWS, Google Cloud, and Microsoft. The company assists organizations with migrating critical workloads of mainframe data to the Cloud.
Further reading on tcVISION from AWS, Google Cloud, and Confluent:
tcVISION supports a vast array of integration scenarios throughout the enterprise, providing easy and fast data migration for mainframe application modernization projects. This innovative technology offers comprehensive abilities to identify and capture changes occurring in mainframe and relational databases, then publish the required information to an impressive variety of targets, both Cloud and on-premises.
tcVISION acquires data in bulk or via CDC methods from virtually any IBM mainframe data source (Software AG Adabas, IBM Db2, IBM VSAM, CA IDMS, CA Datacom, and sequential files), and transform and deliver to a wide array of Cloud and Open Systems targets, including AWS, Google Cloud, Microsoft Azure, Confluent, Kafka, PostgreSQL, MongoDB, etc. In addition, tcVISION can extract and replicate data from a variety of non-mainframe sources, including Adabas LUW, Oracle Database, Microsoft SQL Server, IBM Db2 LUW and Db2 BLU, IBM Informix, and PostgreSQL.
Contact Treehouse Software for a tcVISION Demo Today…
Simply fill out our tcVISION Demonstration Request Form and a Treehouse representative will be contacting you to set up a time for your requested demonstration.
by Joseph Brady, Director of Business Development and Cloud Alliance Leader at Treehouse Software, Inc.
Many customers embarking on Mainframe-to-Cloud data replication projects with Treehouse Software are looking at high availability (HA) as a key consideration in the planning process. All of the major Cloud platforms have robust HA infrastructures that keep businesses running without downtime or human intervention when a zone or instance becomes unavailable. HA basic principles are essentially the same across all Cloud platforms.
In this blog, our example shows how the AWS Global Infrastructure and HA is architected with Treehouse Software’s tcVISION real-time mainframe data replication product. A well planned HA architecture ensures that systems are always functioning and accessible, with deployments located in various Availability Zones (AZs) worldwide.
The following example describes tcVISION‘s HA Architecture on AWS. During tcVISION ’s Change Data Capture (CDC) processing for mainframe data replication on the Cloud, HA must be maintained. The Amazon Elastic Compute Cloud (Amazon EC2), which contains the tcVISION Agent, is part of an Auto Scaling Group that is spread across AZs with Amazon EC2 instance(s).
tcVISION and AWS overall architecture…
Upon failure, the replacement Amazon EC2 instance tcVISION Agent is launched and communicates its IP address to the mainframe tcVISION Agent. The mainframe tcVISION Agent then starts communication with the replacement Amazon EC2 tcVISION Agent.
Once the Amazon EC2 tcVISION Agent is restarted, it continues processing at its next logical restart point, using a combination of the LUW and Restart files. LUW files contain committed data transactions not yet applied to the target database. Restart files contain a pointer to the last captured and committed transaction and queued uncommitted CDC data. Both file types are stored on a highly available data store, such as Amazon Elastic File System (EFS).
tcVISION and AWS HA architecture…
For production workloads, Treehouse Software recommends turning on Multi-AZ target and metadata databases.
To keep all the dynamic data in an HA architecture, tcVISION uses EFS, which provides a simple, scalable, fully managed elastic file system for use with AWS Cloud services and on-premises resources. It is built to scale on-demand to petabytes without disrupting applications, growing and shrinking automatically as you add and remove files, eliminating the need to provision and manage capacity to accommodate growth.
More information on AWS HA
Treehouse Software helps enterprises immediately start synchronizing their mainframe data on the Cloud, Hybrid Cloud, and Open Systems to take advantage of the most advanced, scalable, secure, and highly available technologies in the world with tcVISION…
tcVISION supports a vast array of integration scenarios throughout the enterprise, providing easy and fast data replication for mainframe application modernization projects and enabling bi-directional data replication between mainframe, Cloud, Open Systems, Linux, Unix, and Windows platforms.
Contact Treehouse Software for a Demo Today…
Just fill out the tcVISION Product Demonstration Request Form and a Treehouse representative will contact you to set up a time for your tcVISION demonstration. This will be a live, on-line demonstration that shows tcVISION replicating data from the mainframe to a Cloud target database.
by Joseph Brady, Director of Business Development / Cloud Alliance Lead at Treehouse Software, Inc.
Many customers embarking on Mainframe-to-Cloud data replication projects with Treehouse Software are looking at high availability (HA) as a key consideration in the planning process. The goal with HA is to ensure that systems are always functioning and accessible, with deployments located in various Availability Zones (AZs) worldwide. Having an HA architecture in place protects against data center, availability zone, server, network, and storage subsystem failures to keep businesses running without downtime or human intervention.
In this blog, we will give a high-level overview of tcVISION HA Architecture, using AWS as an example. However, HA basic principles are essentially the same across all Cloud platforms.
Example of the tcVISON HA Architecture on AWS
During tcVISION’s Change Data Capture (CDC) processing for Mainframe-to-Cloud data replication, HA must be maintained in the AWS environment. The Amazon Elastic Compute Cloud (Amazon EC2), which contains the tcVISION Manager, is part of an Auto Scaling Group that is spread across AZs with Amazon EC2 instance(s).
Upon failure, the replacement Amazon EC2 instance tcVISION Manager is launched and communicates its IP address to the mainframe tcVISION Manager. The mainframe tcVISION Manager then starts communication with the replacement Amazon EC2 tcVISION Manager.
Once the Amazon EC2 tcVISION Manager is restarted, it continues processing at its next logical restart point, using a combination of the LUW and Restart files. LUW files contain committed data transactions not yet applied to the target database. Restart files contain a pointer to the last captured and committed transaction and queued uncommitted CDC data. Both file types are stored on a highly available data store, such as Amazon Elastic File System (EFS).
For production workloads, Treehouse Software recommends turning on Multi-AZ target and metadata databases.
To keep all the dynamic data in an HA architecture, tcVISION uses EFS, which provides a simple, scalable, fully managed elastic file system for use with AWS Cloud services and on-premises resources. It is built to scale on-demand to petabytes without disrupting applications, growing and shrinking automatically as you add and remove files, eliminating the need to provision and manage capacity to accommodate growth.
Treehouse Software can help organizations immediately start moving their mainframe data to the Cloud and take advantage of the most advanced, scalable, secure, and highly available technologies in the world with tcVISION…
tcVISION supports a vast array of integration scenarios throughout the enterprise, providing easy and fast data migration for mainframe application modernization projects and enabling bi-directional data replication between mainframe, Cloud, Open Systems, Linux, Unix, and Windows platforms.
Just fill out the Treehouse Software Product Demonstration Request Form and a Treehouse representative will contact you to set up a time for your tcVISION demonstration. This will be a live, on-line demonstration that shows tcVISION replicating data from the mainframe to a Cloud target database.
Treehouse Software’s, “AWS Architectural Considerations and Challenges When Bringing a Product to the AWS Marketplace” will be presented by Andy Jones, Senior Technical Representative and AWS Certified Solutions Architect for Treehouse Software.
Treehouse Software will also be providing food and drinks for the Meetup.
Date/Time: Tuesday, April 9, 2019 • 7:00 PM to 9:00 PM
Place: Bakery Square – UPMC Enterprises • 6425 Penn Ave. #200 · Pittsburgh, PA
Agenda:
07:00 – 07:15 => Grab food, beverage, and a seat
07:15 – 07:20 => Introductions from Nathan Menge (AWS Pittsburgh User Group Organizer)
07:20 – 08:30 => Topic: “AWS Architectural Considerations and Challenges When Bringing a Product to the AWS Marketplace” – Presentation by Andy Jones, Senior Technical Representative and AWS Certified Solutions Architect for Treehouse Software

 How does it work?
How does it work?