
by Joseph Brady, Director of Business Development at Treehouse Software, Inc. and Dan Vimont, Director of Innovation at Treehouse Software, Inc.
We are beginning to see a pleasant and welcomed trend with Treehouse customers who are looking to modernize their valuable mainframe legacy data on the Cloud—they are including their data science teams in the important planning phase of architecting new Cloud environments and targets. This is especially vital for customers who want to incorporate advanced analytics and ML/AI in their strategic data usage plans on the Cloud. Who can contribute better understandings of ultimate data usage than your resident data scientists?
We have heard from many of these data scientists that a primary item on their “wish lists” is for a fully managed, AI powered, massively parallel processing (MPP) architecture to extract maximum value and insights. They specifically mention Amazon Redshift as the Cloud data warehouse (which is much more than a data warehouse) of choice for driving digitization across the enterprise, as well as help personalizing customer experiences. Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the highest performance at any scale. To this desire/question, we can answer with a resounding, “Yes, Treehouse Software has got you covered with Redshift connectivity!”.
The Treehouse Software solution…
Enterprise customers have come to Treehouse Software, because we bring not only proven mainframe data replication tools, but deep subject matter expertise in mainframe technologies, as well as the know-how to target relevant AWS offerings, such as Redshift, S3 (including S3 Express One Zone – see our recent blog on S3 Express One Zone), etc.
The Rocket Data Replicate and Sync (RDRS) solution allows customers’ legacy mainframe environment to operate normally while replicating data on AWS. The technology focuses on changed data capture (CDC) when transferring information between mainframe data sources and Cloud-based databases and applications. Through an innovative set of technologies, changes occurring in any mainframe datastore are tracked and captured, and ultimately published to Redshift.
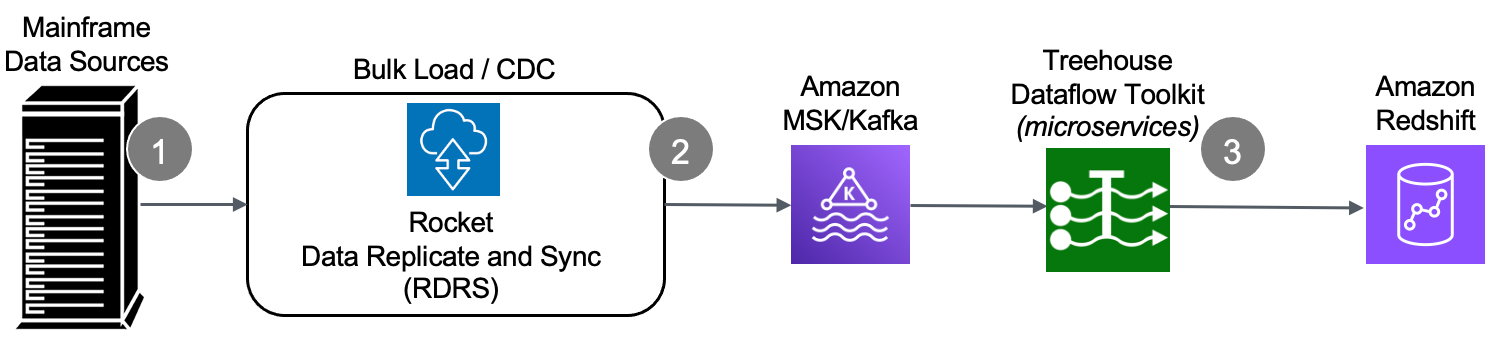 How does it work?
How does it work?
- We start at the source – the mainframe – where an agent (with a very small footprint) extracts data (in the context of either bulk-load or CDC processing).
- The raw data is securely passed from the mainframe to RDRS, which speedily transforms mainframe-formatted data into Unicode/JSON and publishes the results to a Kafka topic.
- Our efficient, autoscaling microservices take it from there. Treehouse Dataflow Toolkit functions consume the data from Kafka and land it in S3 buckets, where Treehouse’s proprietary crawler technology is used to automatically prepare landing tables, views, and additional infrastructure in Redshift. Thenthe mainframe data is loaded into Redshift (all the while adhering to AWS’ recommended “best practices” for massive data loading, thus assuring shortest and surest loads). The inherent reliability and scalability of the entire pipeline infrastructure assure near-real-time synchronization between mainframe sources and Redshift target tables.
Redshift tables and views: something for everybody
Within this framework, the Redshift staging tables (often referred to as “delta tables”) are constantly accruing historical data, ideally suited for data scientists looking to do trend analysis, predictive analytics, ML, and AI work. For business analysts and others who prefer structured data representations of potentially complex hierarchical data, the Treehouse framework also automatically provides structured user-views, providing the look and feel of a SQL database.
…as innovations move faster along the timeline, keep your options open!
Publishing both bulk-load and CDC data to a reliable and scalable framework like Kafka allows you to maintain a broad array of options to ultimately feed your legacy data to any number of JSON-friendly ETL tools, target datastores, and data analytics packages (some of which may not even have been invented yet!). In addition to Redshift, the Treehouse Dataflow Toolkit also currently targets Snowflake, Amazon DynamoDB, and Amazon Athena/S3.
Video – Introduction to Data Warehousing on AWS with Amazon Redshift…
Contact Treehouse Software today to discuss your project, or to schedule a demo of our Mainframe-to-AWS real-time and bi-directional data replication solution.
