
by Joseph Brady, Director of Business Development at Treehouse Software, Inc. and Dan Vimont, Director of Innovation at Treehouse Software, Inc.

Treehouse Software is helping customers modernize their valuable enterprise data on Cloud and Hybrid Cloud environments without disrupting the existing critical work on their legacy systems. However, a new strategic imperative has been added to the modernization game—the requirement to utilize today’s advanced Analytics/AI/ML-friendly platforms, such as Amazon Redshift, Snowflake, Amazon Athena/S3, Amazon S3 Express One Zone Buckets, as well as Amazon Aurora PostgreSQL, where an ever-expanding array of AI/ML tools are available to generate vital insights from the customer’s data. Many of these customers are already using software tools provided by Treehouse, or other vendors to replicate their data into various target data stores, but also more crucially into Kafka pipelines (i.e., Amazon MSK, Confluent, etc.). Kafka is now the top choice for high-speed streaming of massive volumes of mission critical data, providing stable performance under extreme loads. This is especially valuable for enterprises that require up-to-the-second data delivery for use cases that include e-commerce, financial services, logistics, telecommunications, and government IT.
Traditionally, Treehouse customers utilized our data replication technologies to load legacy data into Kafka pipelines, and that was where our involvement generally ended…
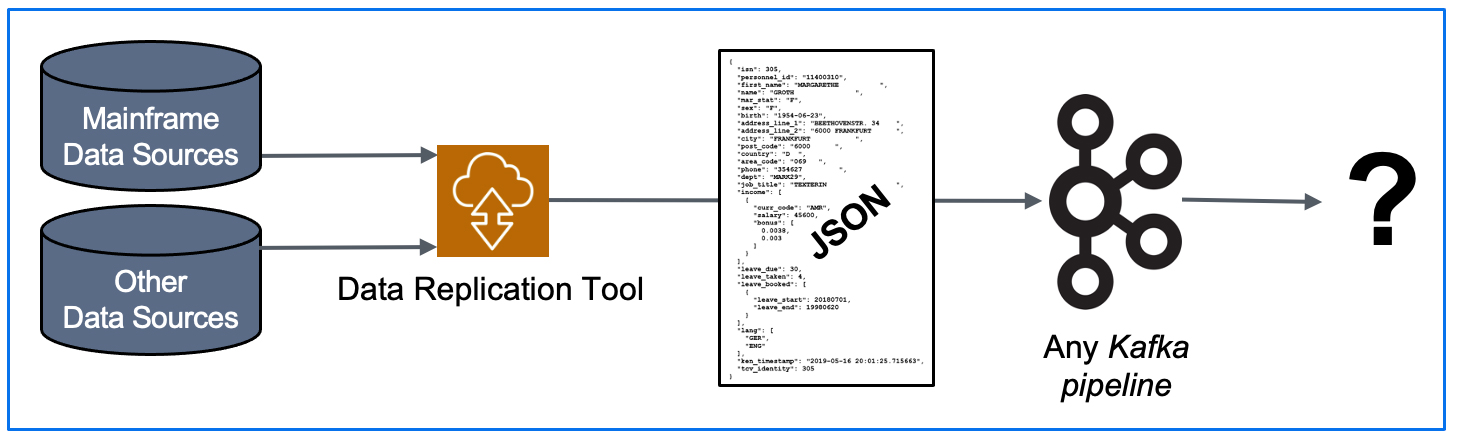
However, once Kafka is designated as a target in the customer’s architecture, we have increasingly become involved in two questions: “What now?”, and/or “What is the best mechanism for us to rapidly transfer data from Kafka to advanced analytics platforms?” Our answer: Look no further than Treehouse Software!
Treehouse Software brings a state-of-the-art, fully automated offering for data transfer from Kafka pipes to Analytics/ML/AI frameworks: the Treehouse Dataflow Toolkit (TDT). TDT is a set of proprietary microservices that assures highly-available, auto-scalable, and event-driven data transfers to your data science teams’ favorite analytics frameworks, all the while adhering to AWS’s and Snowflake’s recommended best practices for massive data loading, thus assuring shortest and surest loads. Additionally, TDT provides a frictionless and instant implementation, accelerating your path to deep data insights for optimizing business processes.
Why do AWS’s and Snowflake’s best practices recommend against using ODBC?
Your data science teams need large quantities of the very latest data in near-real-time, and ODBC doesn’t really do the job, offering only single-threaded, difficult to scale pipes. By contrast, TDT’s approach not only keeps things up-to-date faster than any conceivable ODBC-based solution, but the “delta tables” into which it loads data also inherently retain the entire history of source data ever since the source-to-target synchronization began (perfect for time-based trend/predictive/prescriptive analytics). To load massive quantities of data to a target, TDT uses the target vendors’ (massively scalable) bulk load utilities—not ODBC. It’s vital to note that Snowflake and Redshift are NOT relational (OLTP) databases, so doing CDC transfers to these targets via ODBC (with update, insert, delete transactions) goes directly against “best practices” advice from the vendors, and would almost assuredly result in unwieldy bottlenecks.
What if my data is not on a mainframe?
No worries. Treehouse Software’s messaging is primarily mainframe-centric, since that has been our area of expertise and bread-and-butter for over 40 years. However, data movement is data movement, and if your mainframe, or non-mainframe, data is being pumped to a Kafka pipeline, TDT will take it from there. When a data replication tool publishes both bulk-load and CDC data in JSON format to a reliable and scalable framework like Kafka, it sets the stage for TDT to feed legacy data to any number of JSON-friendly ETL tools, target data stores, and the latest (or yet to be invented) data analytics packages. TDT is the turn-key solution for the easiest and fastest implementation of Kafka data transfer…
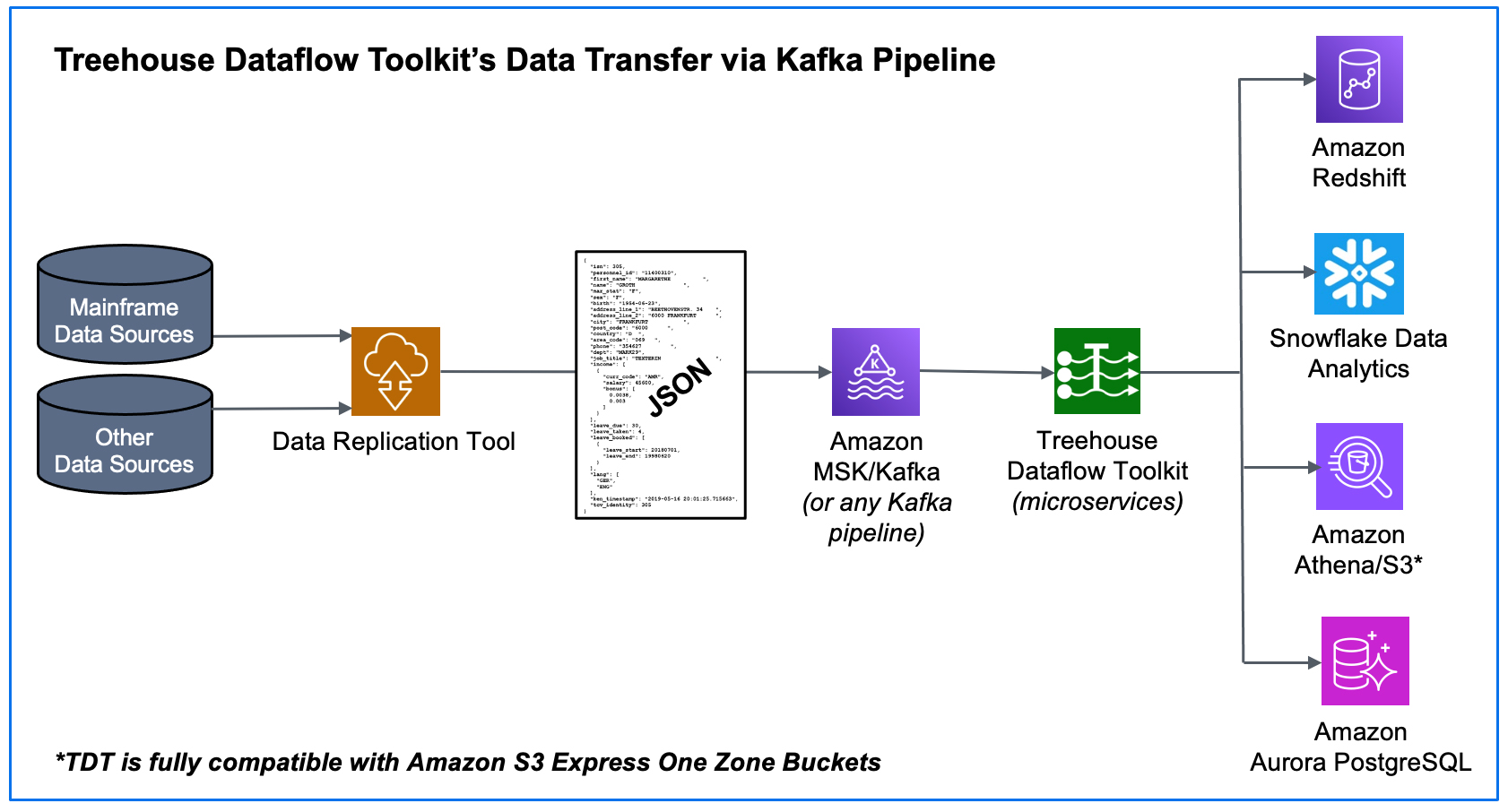
TDT allows you to quickly ramp up your data analytics game by providing a rapid flow of data fresh off your enterprise data systems.
Download: TDT AWS Partner Solution Brief to share with your team…

Treehouse Dataflow Toolkit (TDT) is Copyright © 2024 Treehouse Software, Inc. All rights reserved.

Contact Treehouse Software for a Demo Today!
Contact Treehouse Software today for more information or to schedule a product demonstration.
