by Joseph Brady, Director of Business Development at Treehouse Software, Inc. and Dan Vimont, Director of Innovation at Treehouse Software, Inc.

Introducing Treehouse Dataflow Toolkit…
Many enterprise customers and Cloud platform partners have been coming to Treehouse Software seeking the know-how and technology that enables state-of-the-art transfer of mainframe data to advanced analytics and ML/AI frameworks. In response to this demand, we have designed the Treehouse Dataflow Toolkit (TDT), a set of proprietary microservices that assures highly-available, auto-scalable, and event-driven data transfers to your data science teams’ favorite analytics frameworks.
These customers either already have, or are in the process of acquiring, software tools that replicate their data into Kafka pipelines (i.e., Amazon MSK, Confluent, etc.). Our new and innovative offering, TDT, provides the turn-key solution for getting this data from Kafka into advanced Analytics/AI/ML-friendly targets, such as Amazon Redshift, Snowflake, Amazon Athena/S3, Amazon S3 Express One Zone Buckets, as well as Amazon Aurora PostgreSQL, all the while adhering to AWS’s and Snowflake’s recommended best practices for massive data loading, thus assuring shortest and surest loads.
Market snapshot…
For years, Snowflake and Redshift have been providing “old school” data analytics functionality, and now they are both ramping up their support for ML and GenAI functionality. They are generating the demand (and are doing a good job of it!).
As we’ve been hearing from our customers, it is not a question of, for example: getting their data to either Snowflake OR PostgreSQL OR Redshift, but instead to ALL OF THEM! Each target environment has its own business justifications and reasoning. Many sites will want to do this—send data not only to various RDBMS targets, but also to various Data Analytics targets. The justification for TDT is in a customer’s desire to ramp up its Data Analytics game, quickly and easily with data fresh off the mainframe; and achieving business goals and results faster and at a much lower cost than building a solution themselves.
How does TDT Work?
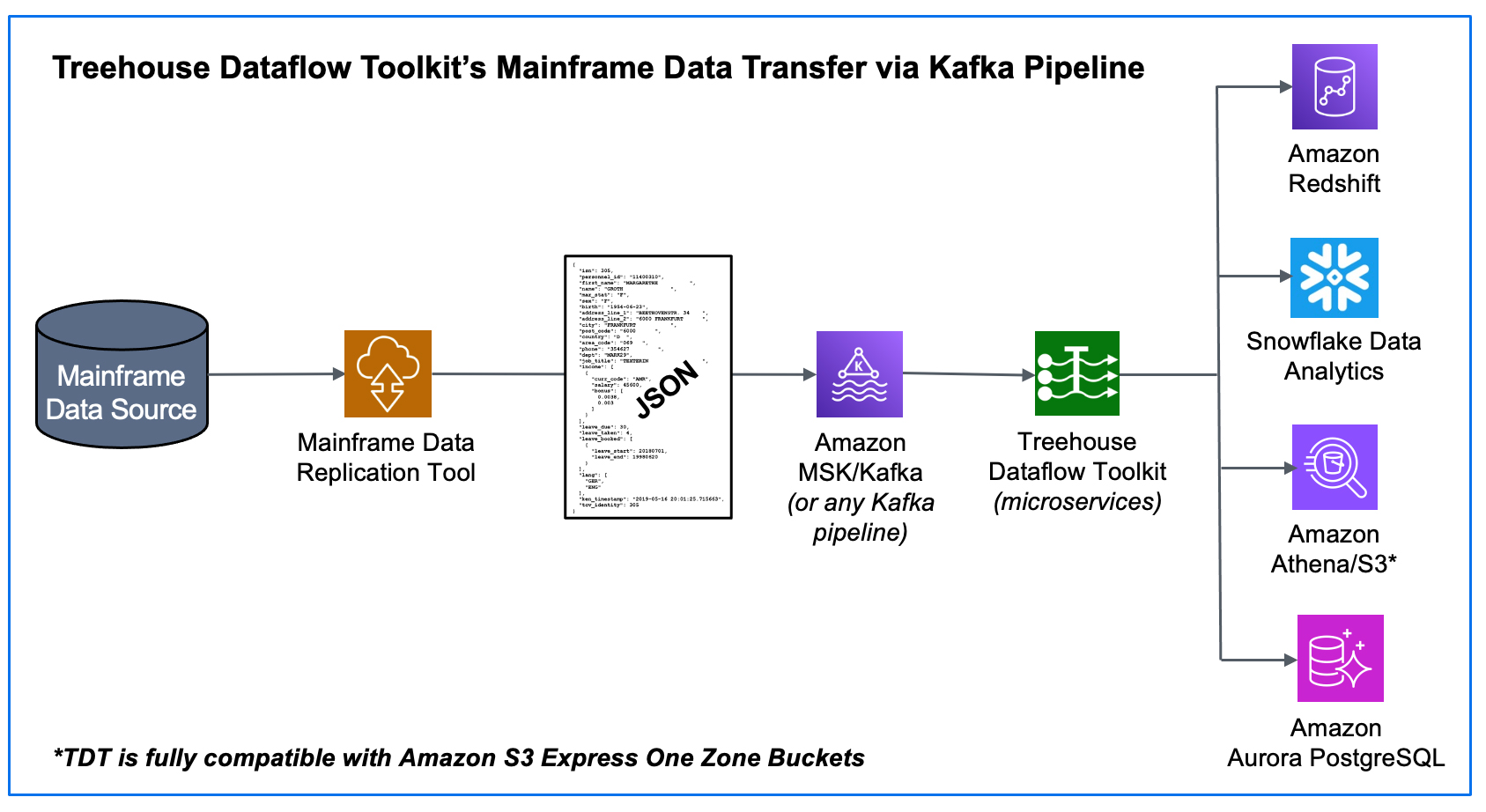
When a mainframe data replication tool (provided by one of Treehouse’s partners) publishes both bulk-load and CDC data in JSON format to a reliable and scalable framework like Kafka, it sets the stage for TDT to feed legacy data from Kafka to any number of JSON-friendly ETL tools, target datastores, and data analytics packages (some of which may not even have been invented yet!).
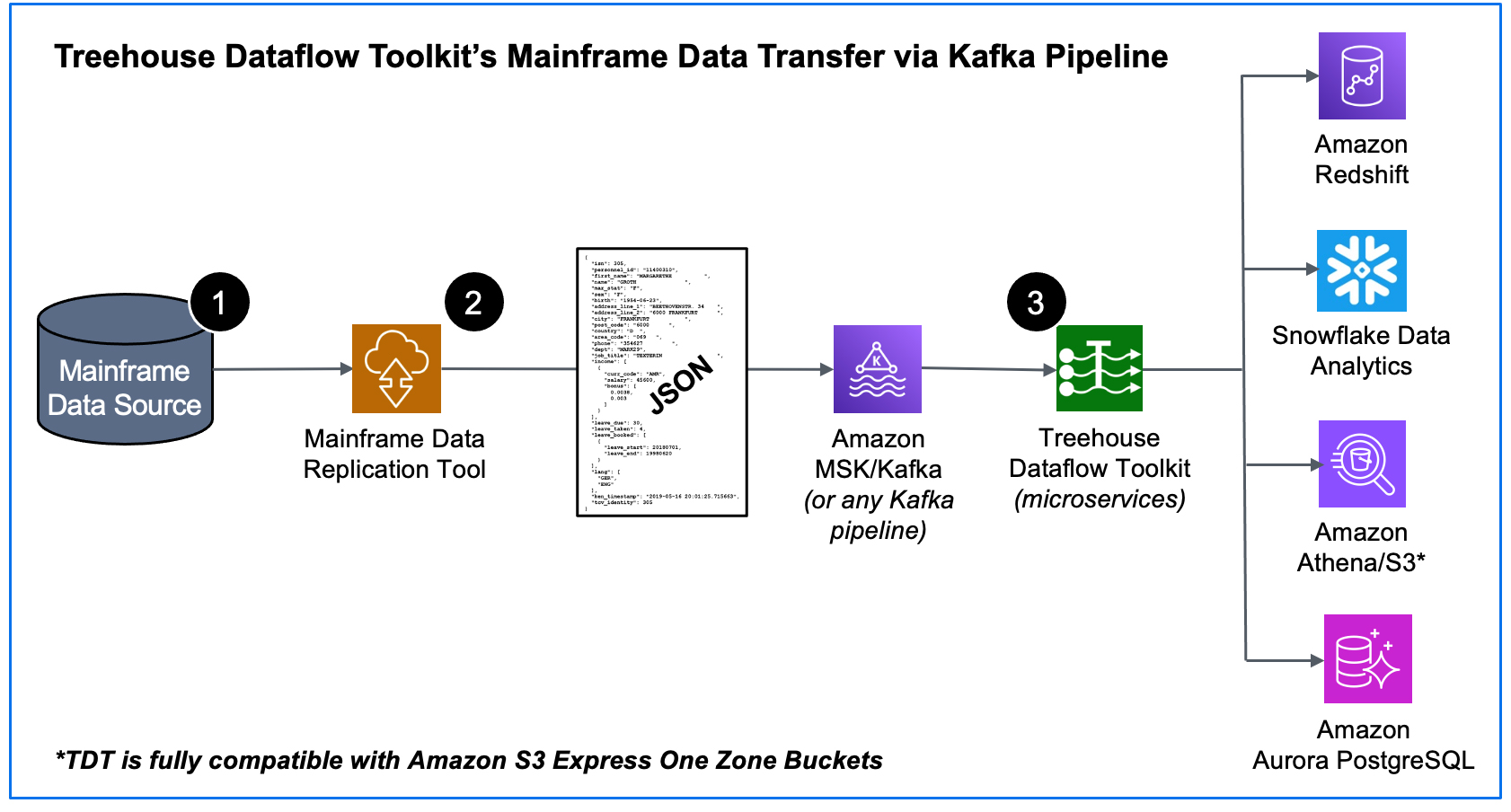
- We start at the source – the mainframe – where an agent (with a very small footprint) extracts data (in the context of either bulk-load or CDC processing).
- The raw data is securely passed from the mainframe by one of our partner’s data replication tools that transforms the data into Unicode/JSON and publishes the results to a Kafka topic (in our example above, a topic in an Amazon MSK cluster).
- TDT microservices consume the data from MSK/Kafka and land it in S3 buckets, where TDT’s proprietary crawler technology is used to automatically prepare landing tables, views, and additional infrastructure for various analytics friendly targets. Then the mainframe data is loaded into Redshift, Snowflake, S3, or PostgreSQL (all the while adhering to AWS’s and Snowflake’s recommended “best practices” for massive data loading, thus assuring shortest and surest loads). The inherent reliability and scalability of the entire pipeline infrastructure assures near-real-time synchronization between mainframe sources and the target tables, even with huge bulk-loads or transaction-heavy CDC processing.
History is enterprise GOLD…
TDT not only keeps things up to date faster than any conceivable ODBC-based solution, but the “delta tables” into which it loads data also inherently retain the entire history of source data ever since mainframe-to-target synchronization began. So, for example, after TDT has been syncing a target table for 5 years, a data scientist now has 5 years’ worth of historical data to work with for trend analysis, predictive analytics, prescriptive analytics, ML, etc.
…but you also need the very latest data in near-real-time.
While TDT’s unique “delta-tables” approach offers comprehensive “history” for advanced analytics, the traditional need for up-to-the-second, current snapshots of mainframe datastores is also completely provided for. Adhering once again to target vendors’ “best practices”, self-materializing views are provided to work with current data, not only in the JSON format in which it is stored, but also in fully-structured views which provide the more traditional look and feel of a SQL database.
Competitive differentiators between TDT and the “connectors”
- TDT provides massive scalability, thanks to the AWS Lambda infrastructure.
- TDT’s delta-table approach means unbeatable throughput (everything is just an INSERT, and it’s all going through the target vendors’ “best-practices” bulk-load utilities).
- TDT’s advanced crawler automatically provides JSON-manipulating VIEWs (often awkward to develop in a SQL context) and other target infrastructure.
- TDT adheres to AWS’s and Snowflake’s recommended best practices for connectivity.
- Other data replication tools that attempt to target Redshift and Snowflake use only generic ODBC connections for data transmission.
- To load massive quantities of data to a target, TDT uses the target vendors’ (massively scalable) bulk load utilities—not ODBC. (Transaction-based ODBC transmissions afford a single, inherently difficult-to-scale pipe.)
- Snowflake and Redshift are NOT relational (OLTP) databases, so doing CDC transfers to these targets via ODBC (with update, insert, delete transactions) goes directly against “best practices” advice from the vendors, and will almost assuredly result in unwieldy bottlenecks.
- For Snowflake’s bulk-load functions to work, the development of additional Snowflake-proprietary objects (in addition to just target tables and views) is required; TDT’s crawler (DDL generator) function for Snowflake automatically generates statements to create these unique objects, along with the standard “create table”, “create view” statements.
- Loading hierarchical data in JSON format (to JSON-friendly environments like Snowflake, Athena/S3, Redshift, and PostgreSQL) is the best methodology for many situations, because it avoids having to split hierarchies out into parent/child/grandchild tables, which have to subsequently be pulled back together again via cumbersome SQL queries in order for the data to be effectively worked with. NOTE that one of our customers has become so frustrated with working with “split apart” parent/child/grandchild structures in PostgreSQL that they want the ability to send their hierarchical data in JSON format TO POSTGRESQL (hence our recent addition of TDT support for PostgreSQL as a target).
- For users who still want to work with data in structured parent/child/grandchild format (yes, many people still may be reluctant to work with JSON in the context of SQL queries), TDT’s crawler (DDL generator) functions provide user-views that exactly emulate those old-school parent/child/grandchild structures.
- Production environment with TDT can be up and running in 2-4 weeks.
- TDT’s SaaS model advantages include: ease of implementation, shorter time to move into production, reliable uptime, instantaneous upgrades, pay-as-you-go billing based on usage metrics, and ease of integration with other SaaS offerings.
Treehouse Dataflow Toolkit (TDT) is Copyright © 2023 Treehouse Software, Inc. All rights reserved.
Contact Treehouse Software for a Demo Today!
Contact Treehouse Software today for more information or to schedule a product demonstration.