
by Joseph Brady, Director of Business Development at Treehouse Software, Inc.; Dan Vimont, Director of Innovation at Treehouse Software, Inc.; and Ram Dhakne, Staff Solutions Engineer at Confluent

The message is clear from our customers—They want to modernize mainframe data on Cloud and Hybrid Cloud environments without disrupting the existing critical work on their legacy systems. They also want to tap into today’s advanced data analytics platforms such as Amazon Redshift, Snowflake, and Amazon Athena/S3, where an ever-expanding array of machine learning and artificial intelligence (ML/AI) tools are available to generate vital insights from their enterprise’s data. Your data science teams are eagerly awaiting the arrival of critical data from your mainframes to supercharge their predictive analytics and generative AI frameworks.
Treehouse Software and Confluent: Two companies providing a reliable and scalable solution…
Confluent Cloud Data Streaming Service
As stated on the Confluent website, “Your team has better things to do than fight Kafka fires.” That is why Confluent Cloud was built as a 10x better, fully managed, and truly Cloud-native service for Apache Kafka, powered by Kora engine. Customers can take data streaming to the next level—sans the Kafka management and operational woes.
Confluent Cloud offers enhanced productivity, improved scalability, minimized downtime, and much more—all while reducing total cost of ownership. Confluent Cloud offers:
- Elastic scaling: Scale up and down quickly to meet fluctuating customer demand, without the ops burden that comes with scaling your data infrastructure
- Infinite Storage: Enable powerful use cases by never having to worry about Kafka retention limits again, while only paying for the storage used
- Built-in Resiliency: Ensure high availability and offload Kafka ops with 99.99% uptime SLA, multi-AZ clusters, and no-touch Kafka patches
Treehouse Software Mainframe CDC Data Replication
Enterprise customers have come to Treehouse Software, because the company brings not only proven mainframe data replication tools, but also deep subject matter expertise in mainframe technologies, as well as the know-how to target relevant offerings especially designed for ingesting data for advanced analytics and ML/AI.
The Rocket Data Replicate and Sync (formerly tcVISION) solution from Treehouse allows customers’ legacy mainframe environment to operate normally while replicating data on Cloud and Hybrid Cloud environments. The technology focuses on changed data capture (CDC) when transferring information between mainframe data sources and Cloud-based databases and applications. Through an innovative set of technologies, changes occurring in any mainframe datastore are tracked and captured, and ultimately published to various Cloud targets. Additionally, the Treehouse Dataflow Toolkit (TDT) set of microservices greatly enhances the architecture’s connectivity to high performance, non-relational, massive parallel processing datastores (Amazon Redshift, Snowflake, Amazon Athena/S3) that are primed to supply the most advanced ML/AI tools to data science teams.
Figure 1: In the longer-term picture, an enterprise can now keep its options open by propagating data to the highly reliable, very scalable Confluent Cloud that can be “subscribed to” by any number of current or yet-to-be-invented ETL toolsets and target datastores.
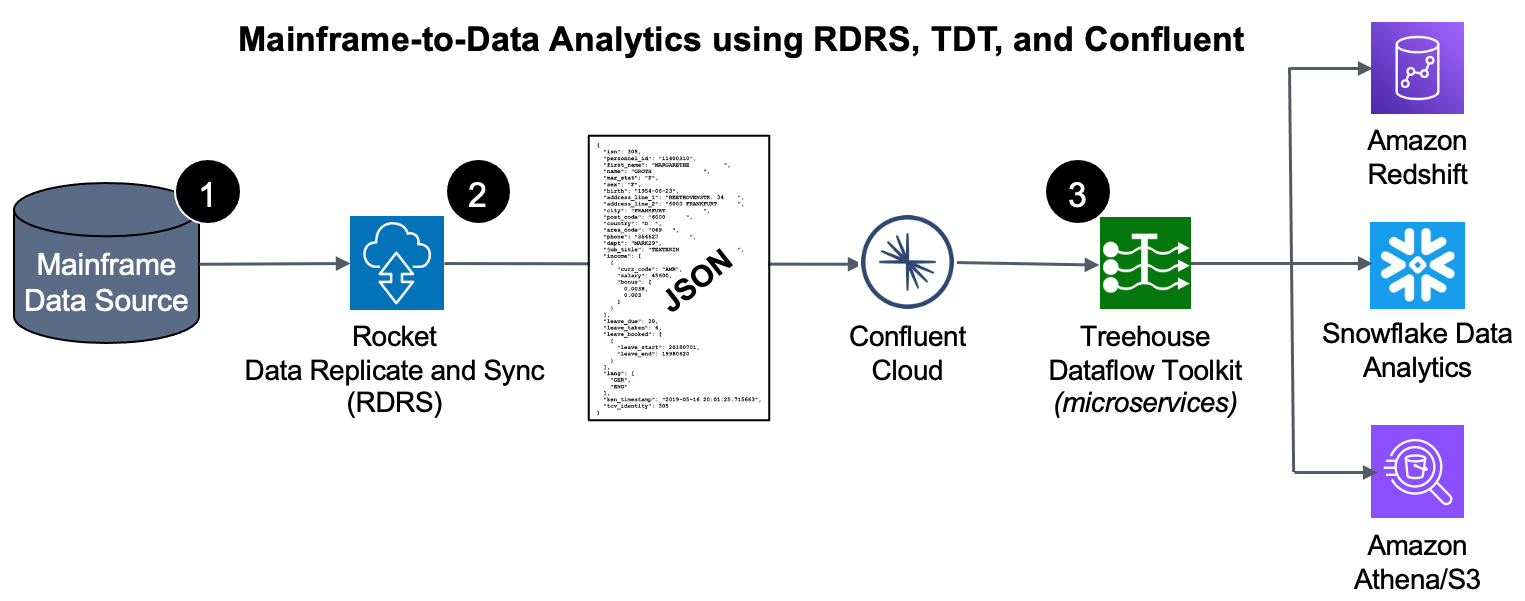
How does it work?
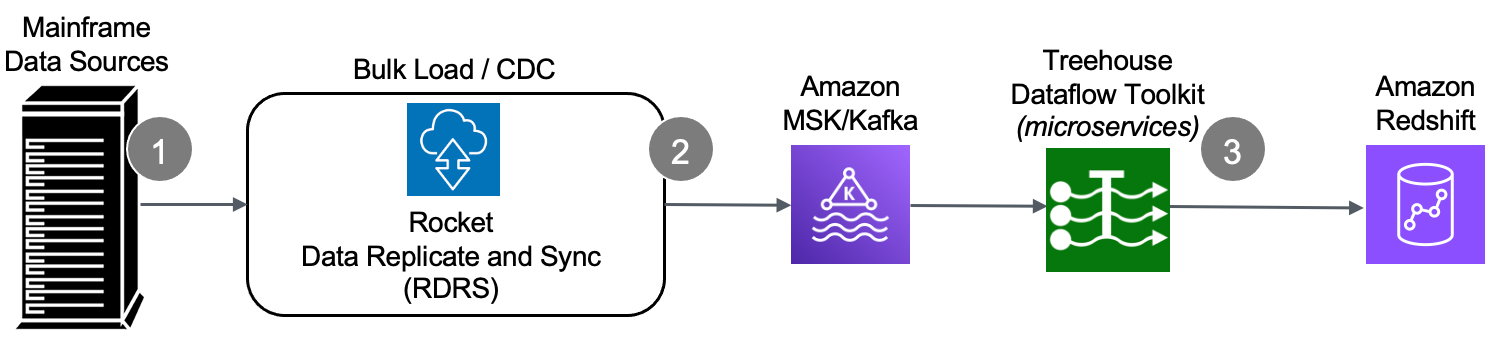
- We start at the source – the mainframe – where an agent (with a very small footprint) extracts data (in the context of either bulk-load or CDC processing).
- The raw data is securely passed from the mainframe to Rocket Data Replicate and Sync (RDRS) which speedily transforms mainframe-formatted data into Unicode/JSON and publishes the results to a Kafka topic in Confluent Cloud.
- The Treehouse Dataflow Toolkit functions consume the data from Confluent and land it in S3 buckets, where Treehouse’s proprietary crawler technology is used to automatically prepare landing tables, views, and additional infrastructure for various analytics friendly targets. Then the mainframe data is loaded into Redshift, Snowflake, or S3 (all the while adhering to AWS’ and Snowflake’s recommended “best practices” for massive data loading, thus assuring shortest and surest loads). The inherent reliability and scalability of the entire pipeline infrastructure assure near-real-time synchronization between mainframe sources and the target tables.
The very latest data—delivered!
Figure 2: RDRS, Confluent, and TDT work in tandem to easily replicate mainframe data and create target Snowflake resources for a wide variety of end use.
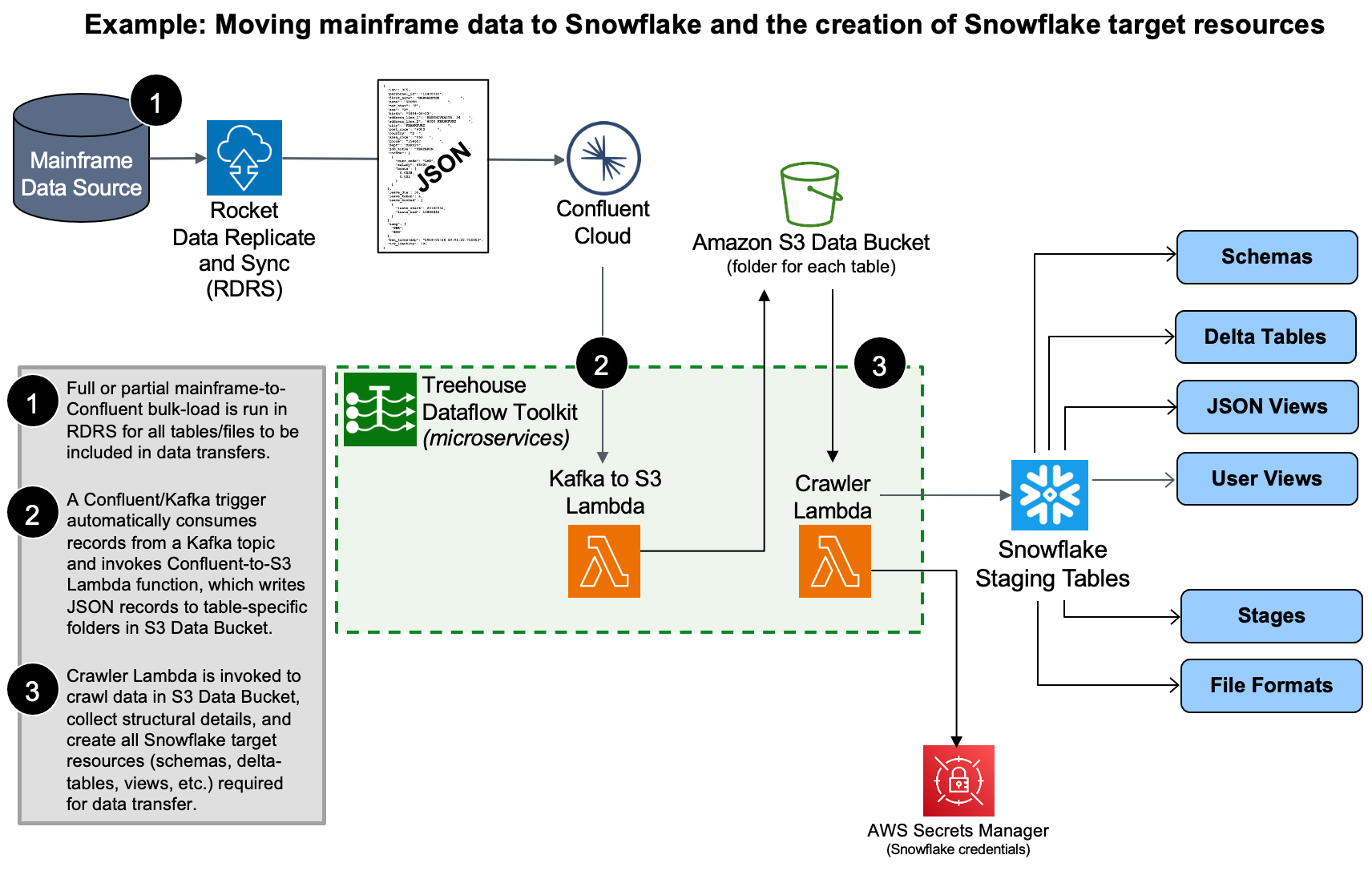
Figure 3: TDT adheres to Snowflake’s recommended “best practices” for bulk loading of mainframe data by using its COPY function to load data from S3
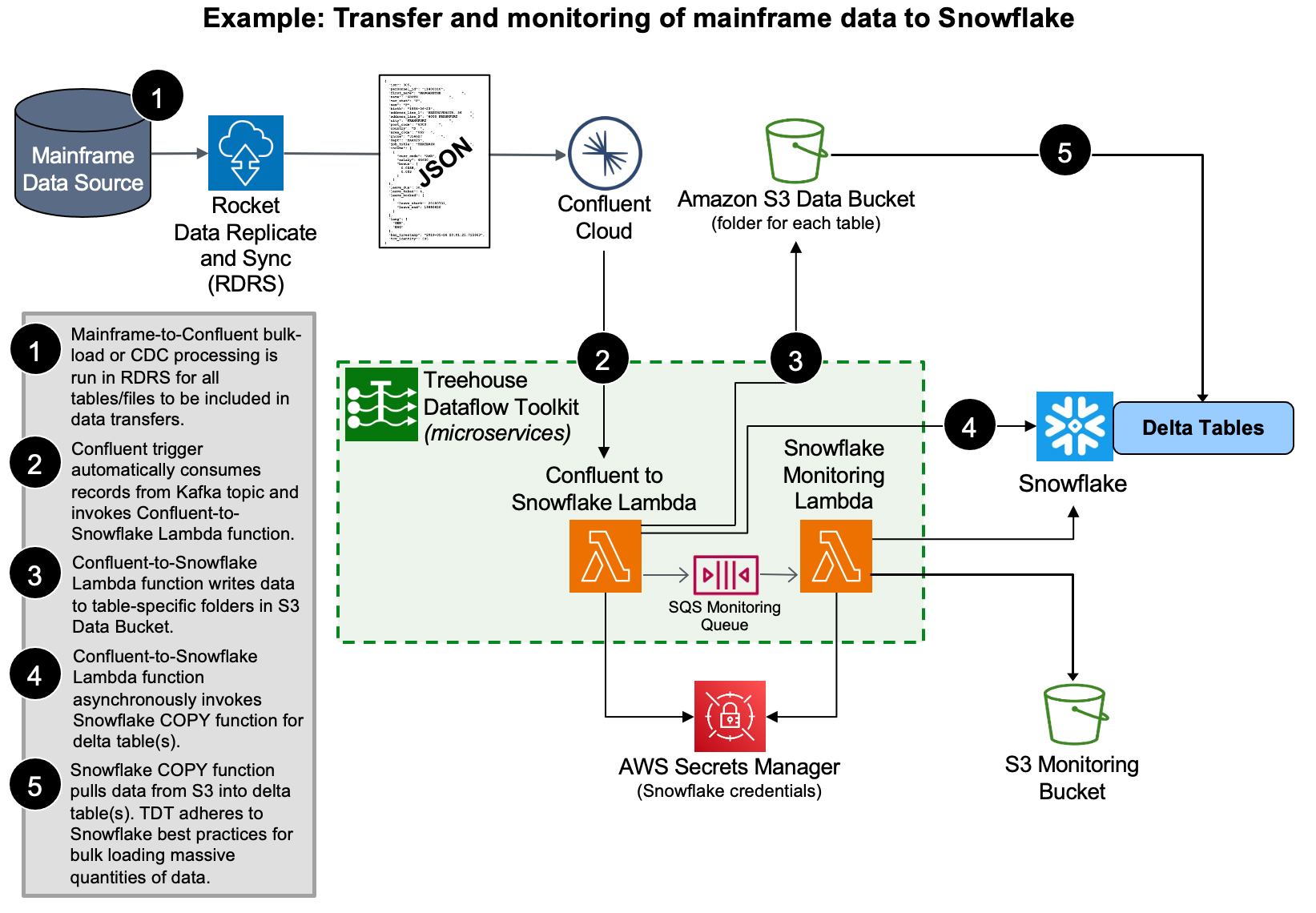
This Treehouse/Confluent framework allows data in staging tables to be constantly accruing the most current data, ideally suited for data scientists looking to do trend analysis, predictive analytics, ML, and AI work. For business analysts and others who prefer structured data representations of potentially complex hierarchical data, this framework also automatically provides structured user-views, providing the look and feel of a SQL database.
Contact Treehouse Software for a Demo Today!
Contact Treehouse Software today for more information or to schedule a product demonstration.
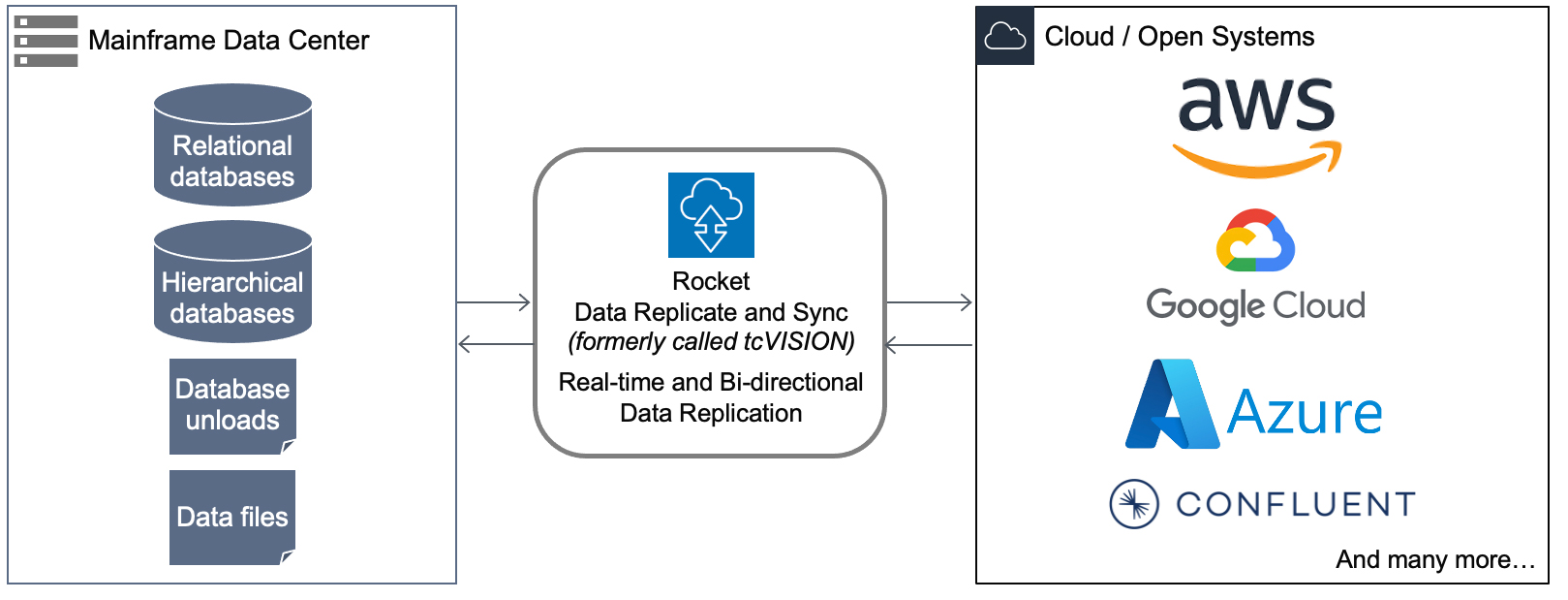
 How does it work?
How does it work?