Many have seen the announcement that Rocket Software has acquired BOS DigiTec GmbH, developer of tcVISION, which Treehouse Software markets, sells, and supports worldwide. We congratulate both companies on this exciting move to grow the product’s presence in the enterprise modernization market. Please note that Treehouse Software, Inc. was not mentioned in that announcement, because Treehouse is not part of this acquisition. However, our customers, partners, and prospects that we do business with should not be concerned and can be assured that Treehouse Software is still your source and point of contact for the tcVISION and tcACCESS products for years to come. After discussions with the Rocket Software team, we received the following statement for which we are grateful. We would like to share this statement from Rocket Software:

Dear Treehouse Customers,
We are thrilled to share some exciting news about tcVISION and tcACCESS, the products that have become your trusted solutions for data integration. BOS DigiTec GmbH, the German developer behind tcVISION and tcACCESS, has recently entered into a definitive agreement to be acquired by Rocket Software, a global technology leader that develops enterprise software for some of the world’s largest companies.
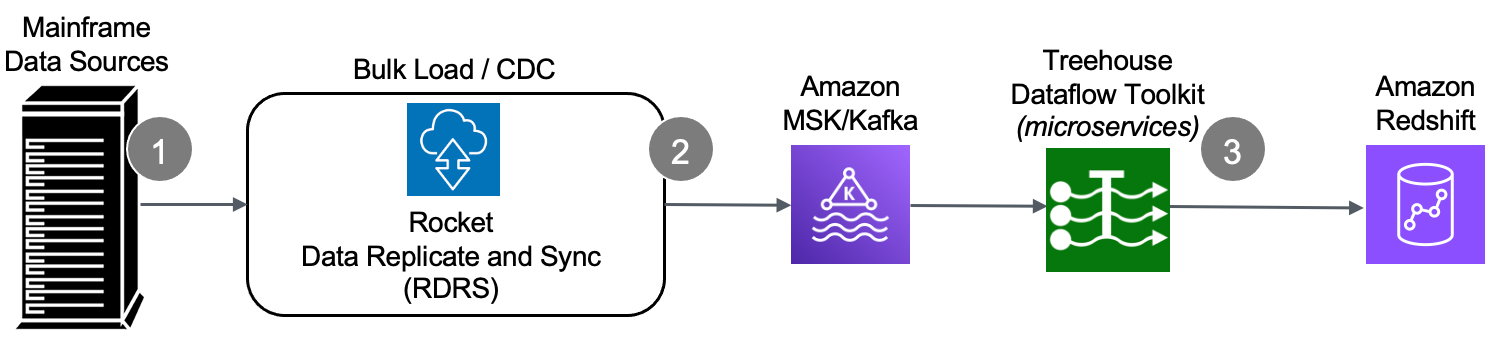
As a result of this acquisition, tcVISION will now be rebranded as Rocket Data Replicate and Sync (RDRS) and will become an essential part of Rocket Software’s portfolio of modernization products. tcVISION, now RDRS, will serve as Rocket Software’s primary solution for real-time data replication, complementing their Rocket Data Virtualization solution (RDV), which focuses on providing modern APIs to access current mainframe data in place.
While the product’s name is changing, we want to assure you that it will remain the same exceptional solution you have come to know and trust from Treehouse Software. It’s the same technology with a new name. Treehouse Software, in collaboration with Rocket Software, is committed to keeping you well-informed throughout this transition.
Here is some additional information:
- Who is Rocket Software and what do they do? Rocket Software partners with the largest enterprises across all industries globally to address their most complex IT challenges in infrastructure, data, and applications. Trusted by over 10,000 customers, Rocket Software enables enterprises to modernize in place with a hybrid cloud strategy, avoiding the need for costly re-platforming. Rocket Software is a privately held U.S. corporation headquartered in the Boston area, with centers of excellence strategically located throughout North America, Europe, Asia, and Australia.
- How will the acquisition affect tcVISION’s product roadmap? RDRS, formerly tcVISION, will be integrated into Rocket Software’s portfolio of modernization products, promising enhanced scale, flexibility, and security for your organization’s existing infrastructure. Given Rocket Software’s global reach, we anticipate that product roadmaps and requests for enhancements will accelerate, and we look forward to sharing more details soon, as we prioritize listening to and addressing customer needs.
- How will this acquisition help you? This acquisition will combine Rocket Software’s extensive mainframe portfolio and expertise with the tcVISION (RDRS) data replication capabilities, offering Treehouse Software’s customers the best of both worlds—the security and reliability of the mainframe and the advanced analytics of the cloud, all without incurring excessive business risk or expenses. This combination allows you to keep core transaction processing workloads secure on the mainframe while benefiting from real-time data replication to the cloud, enabling the development of new applications and generative AI models simultaneously.
- How will our customer support be affected? Your customer support experience with Treehouse Software remains unchanged and Treehouse is your point of contact for support. Rocket Software, like Treehouse Software, is dedicated to putting customers first, and your success remains our shared priority.
- Will there be any interruptions in services during the transition? No, there will be no interruptions in services during the transition.
- Who can I contact with questions? You can reach out to Treehouse Software team members, Joseph Brady, Director of Business Development at: jbrady@treehouse.com or Lynn McIntyre, Technical Support Leader at: lmcyntire@treehouse.com. For sales-related questions, contact: sales@treehouse.com.
- Where is Rocket Software located and what markets does it serve? Rocket Software is headquartered in Waltham, MA, USA, and operates globally with offices in North America, Europe, and Asia/Pacific. It serves a wide range of industries, including Aerospace & Defense, Auto Manufacturing, Banking & Finance, Education, Energy, Government, Healthcare, Insurance, and Retail, among others.
- How big is Rocket Software? Rocket Software has over 2,500 employees worldwide.
This collaboration between Treehouse Software, a mainframe systems software company since 1983, and a global technology leader like Rocket Software marks a significant milestone in our journey to provide you with even better solutions and services.
We sincerely appreciate the trust and loyalty you have shown us. If you have any questions or require further information, please do not hesitate to reach out to your contact at Treehouse Software. Your satisfaction and success remain our top priority, and we are here to support you every step of the way.
Thank you for your continued partnership with Treehouse Software, and we look forward to delivering even more value to you through this exciting new collaboration with Rocket Software.

Conclusion from Treehouse Software…
Treehouse Software has been in business over 40 years, serving enterprise mainframe customers worldwide, and look forward to many more years of innovation and presence in this market space. Additionally, Treehouse Software has been representing tcVISION (now RDRS) for 17 years providing marketing, sales, trials, POCs, tech support, QA/testing, etc. which will continue, uninterrupted.
Please contact Treehouse Software at sales@treehouse.com with any questions. We look forward to serving you in your modernization journey!
Treehouse Software, Inc. | 2605 Nicholson Rd, Suite 1230 | Sewickley, PA 15143 | USA
T: 1-724-759-7070 | W: www.treehouse.com and www.tcvision.com

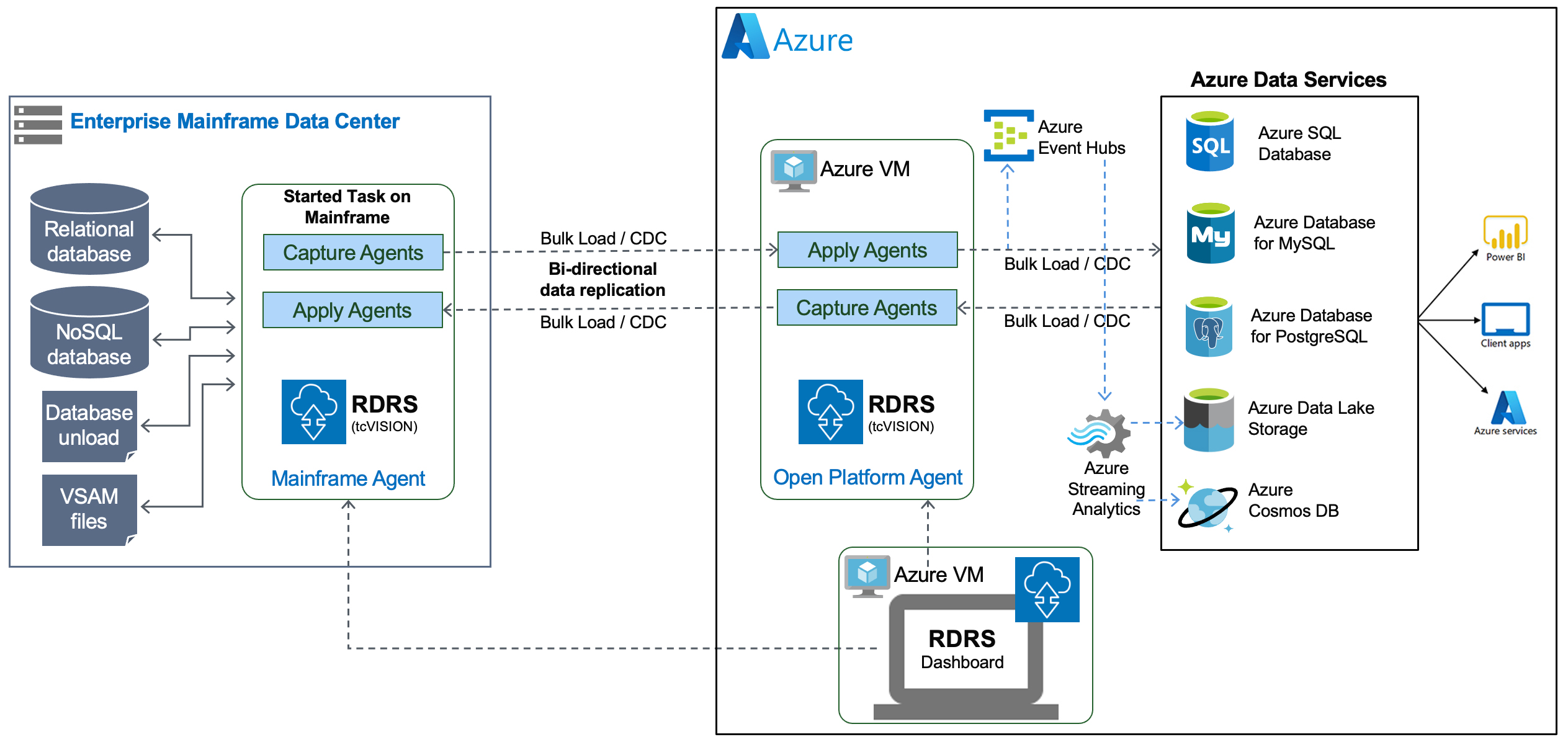
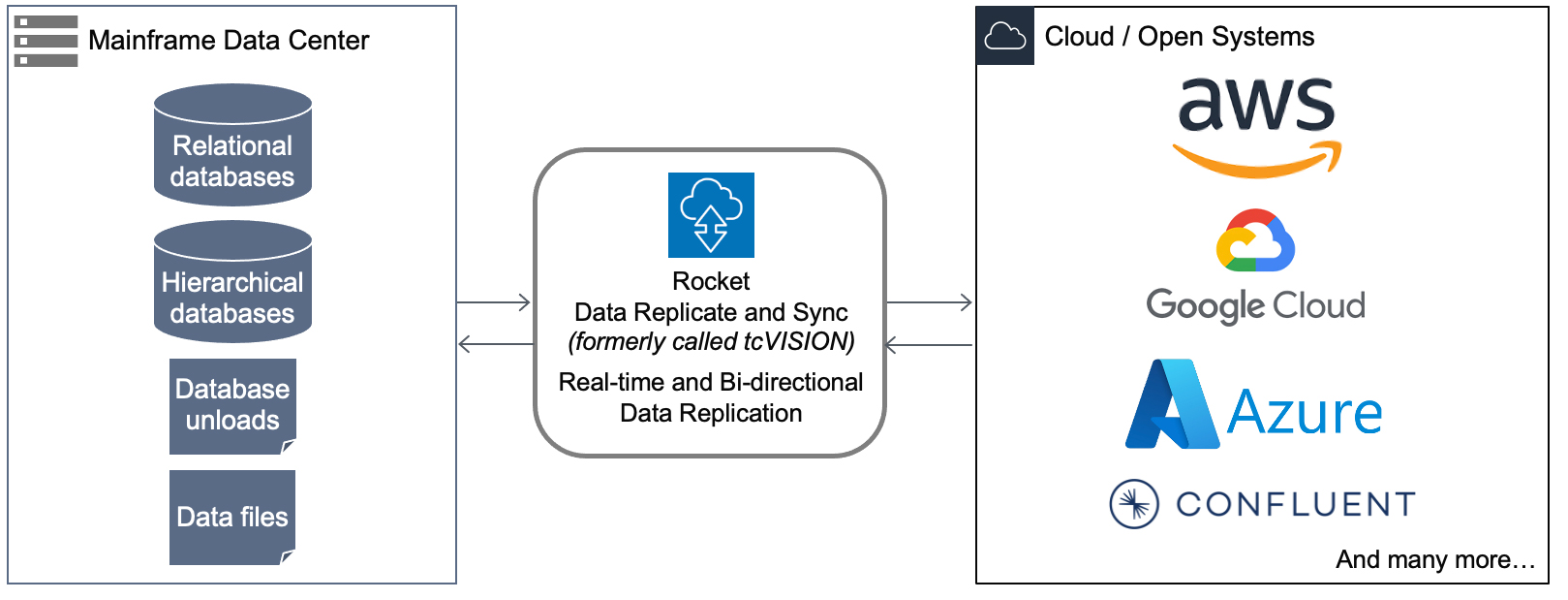
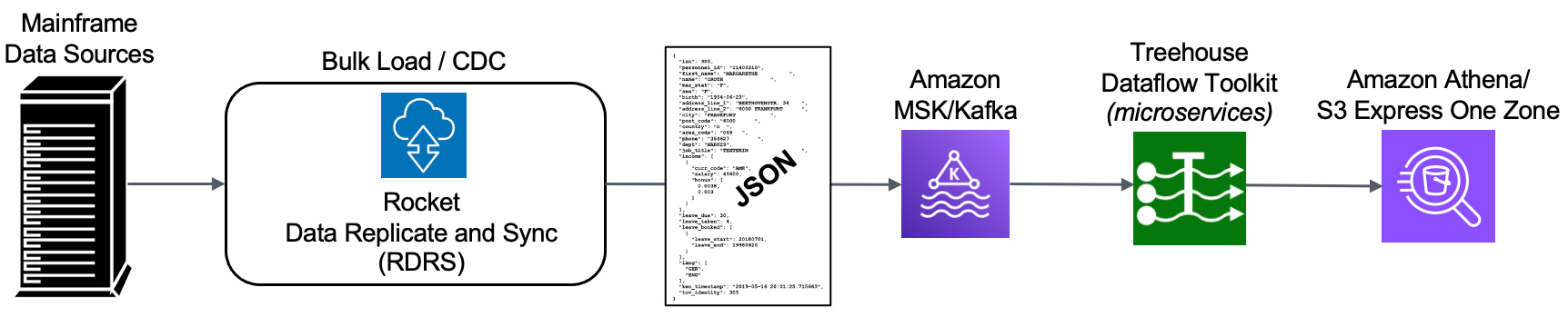
 How does it work?
How does it work?