by Joseph Brady, Director of Business Development at Treehouse Software, Inc. and Dan Vimont, Director of Innovation at Treehouse Software, Inc.

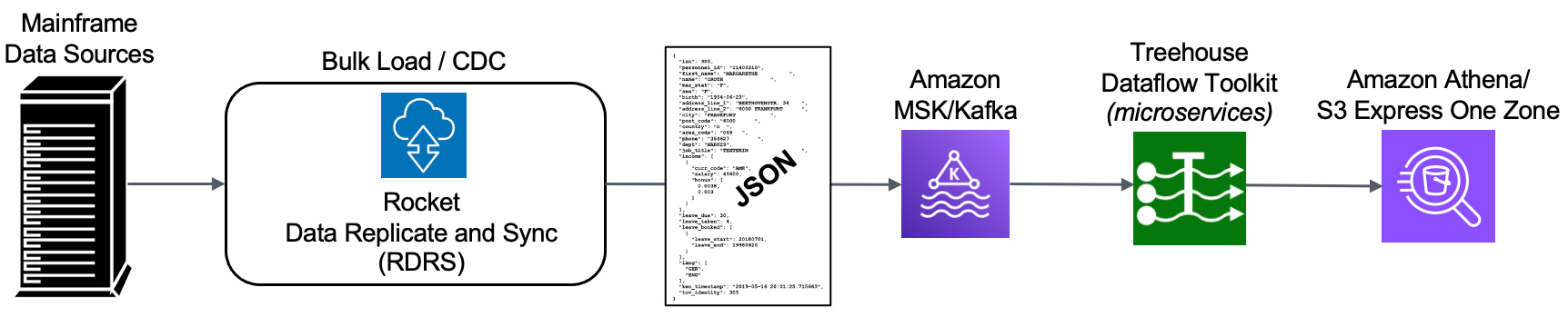
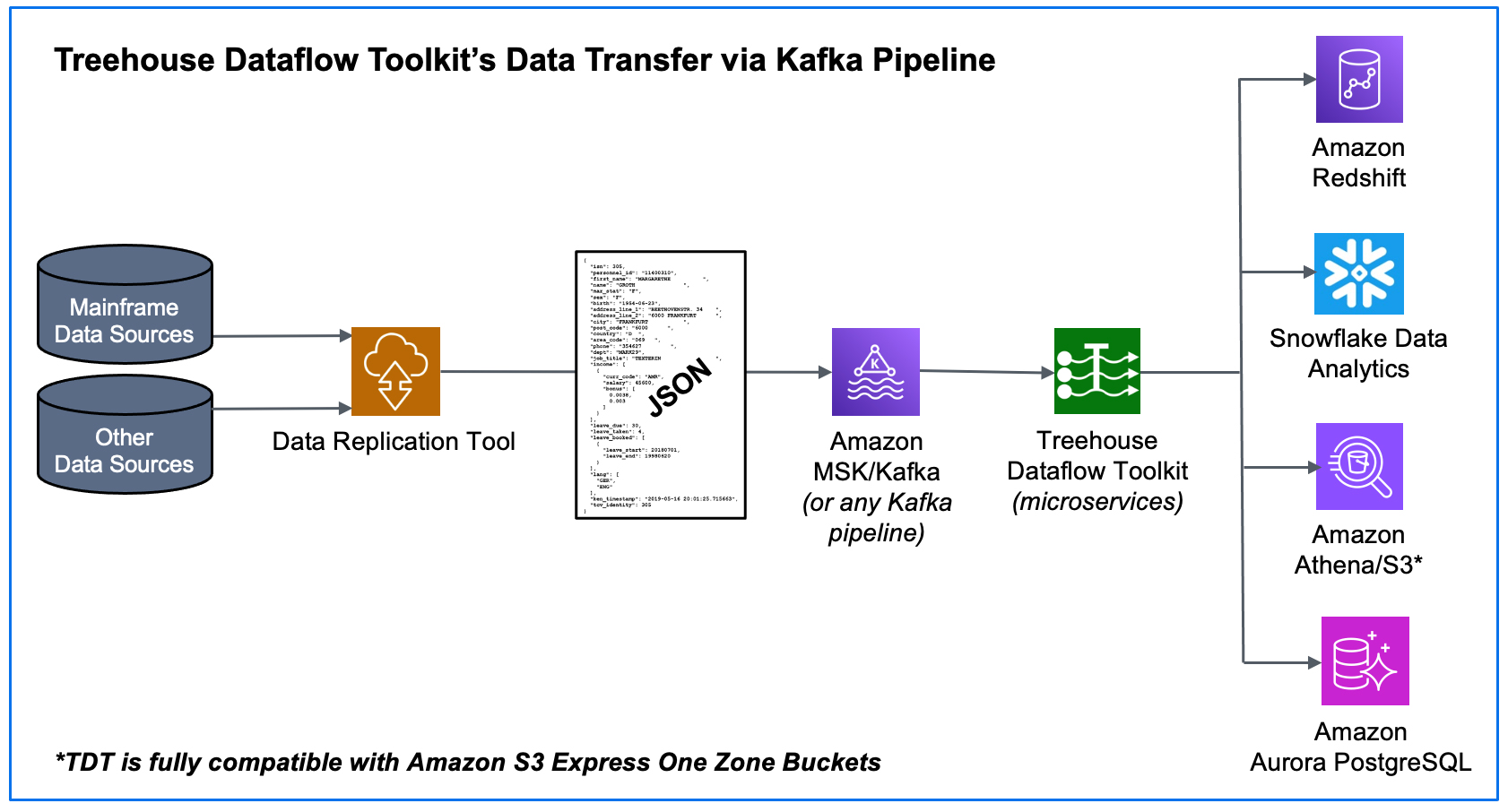
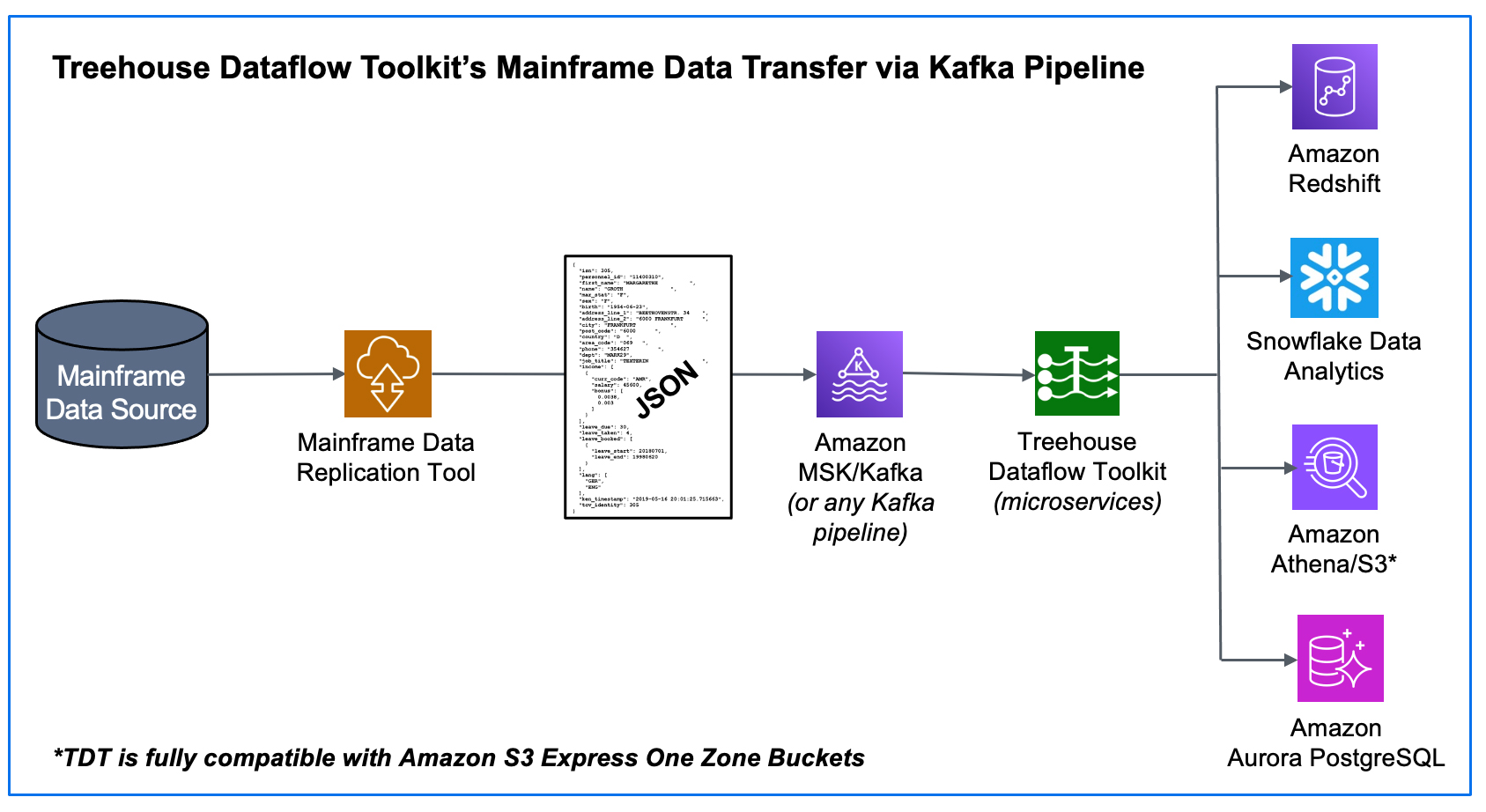
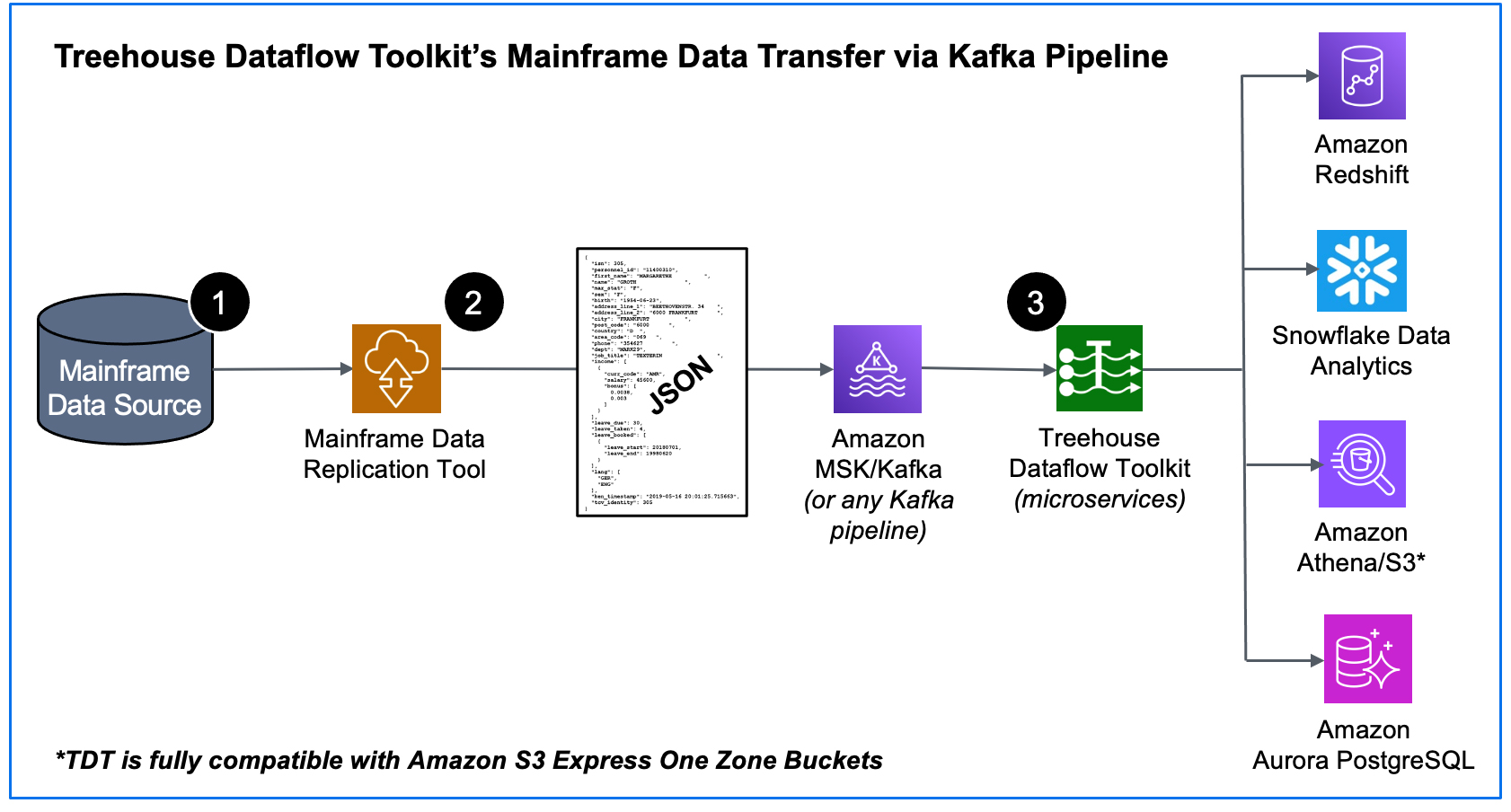
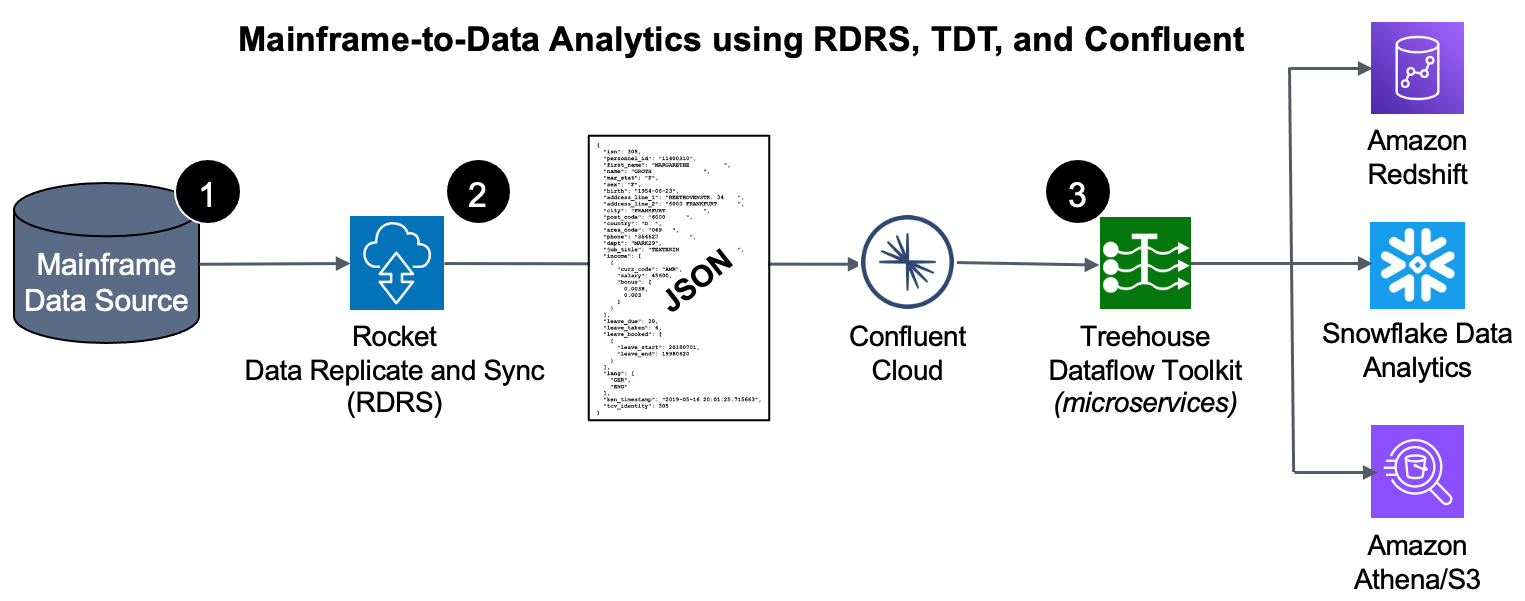
Over the past few months, we have been rolling out information on Treehouse Dataflow Toolkit (TDT), a state-of-the-art, fully automated offering for data transfer from Kafka pipes to Analytics/ML/AI frameworks. TDT is a set of proprietary microservices that assures highly-available, auto-scalable, and event-driven data transfers to your data science teams’ favorite analytics frameworks, such as Snowflake, Amazon Redshift, Amazon Athena/S3, Amazon S3 Express One Zone Buckets, as well as Amazon Aurora PostgreSQL, all the while adhering to AWS’s and Snowflake’s recommended best practices for massive data loading. Make no mistake, TDT is MUCH more than merely a “connector”.
In this blog, we will focus on how TDT handles data transfers to perhaps the most complex environment: Snowflake. Out of all TDT functions and features, our Snowflake connectivity offers the biggest “value added” to customers, because Snowflake has quickly become a top choice for enterprises looking for a Cloud platform onto which they can mobilize data at near-unlimited scale and performance, and bring advanced ML/AI capabilities.
Snowflake overview video…
Connectivity using Snowflake’s best practices vs. traditional ODBC…
TDT’s innovative Lambda-based (microservices) approach enables faster data flow than any conceivable ODBC-based solution, which is the standard tool used for most “roll your own” approaches, or “we have a connector for that” offerings.
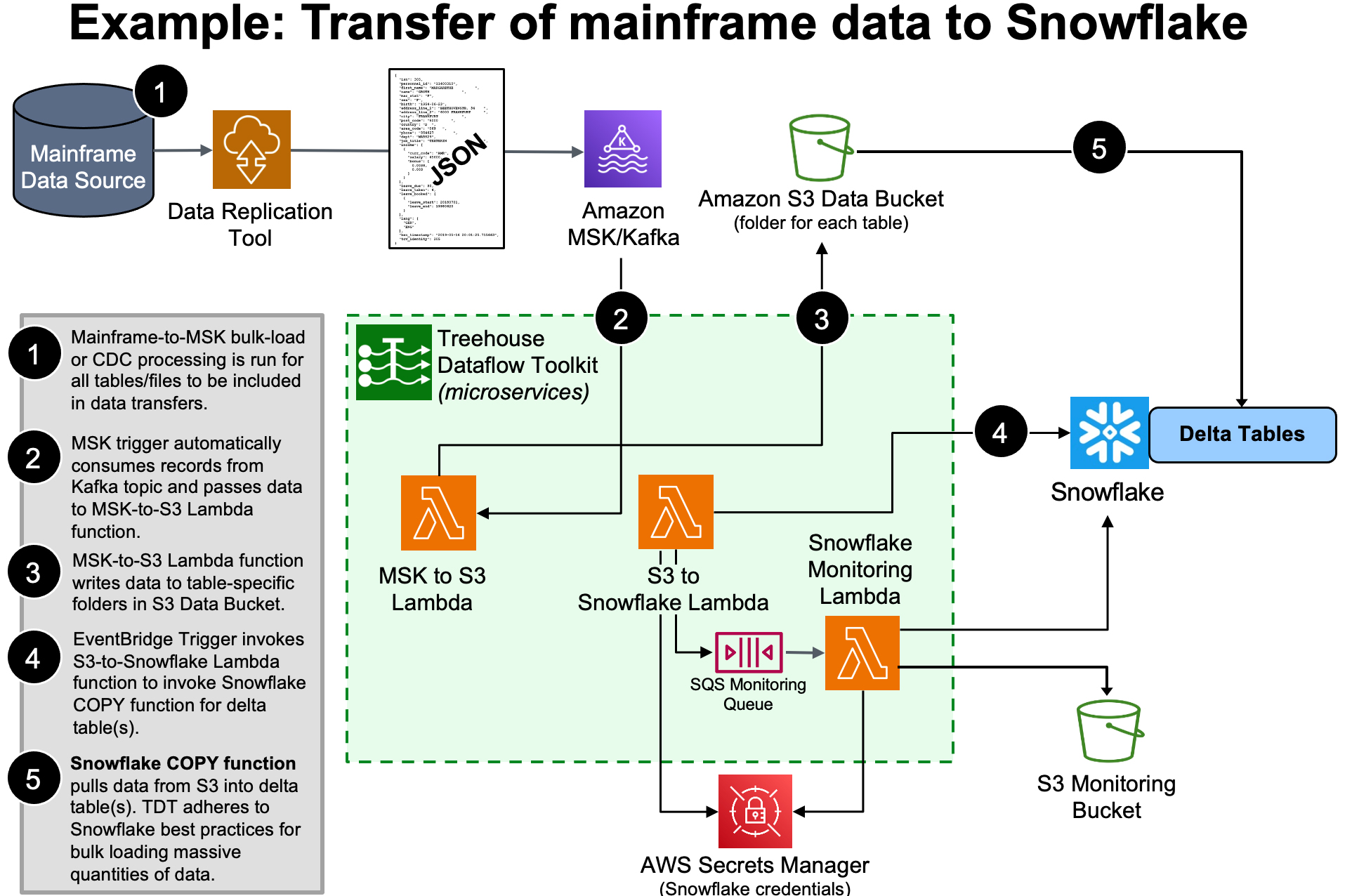
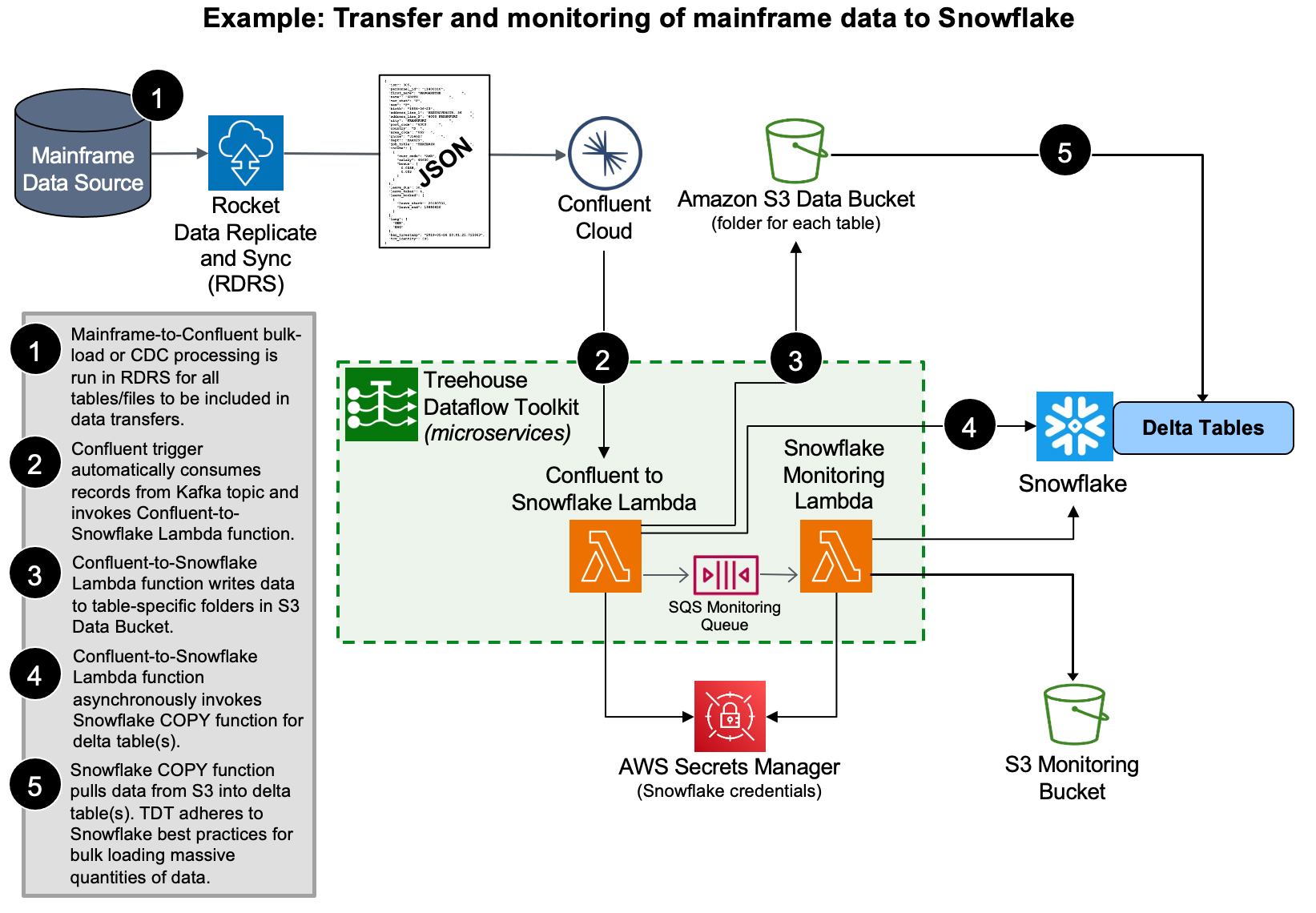
To load massive quantities of data to a target, TDT uses Snowflake’s (hugely scalable) bulk load utilities—not ODBC. It is vital to note that Snowflake is NOT a relational (OLTP) database, so doing CDC transfers to these targets via ODBC (with update, insert, delete transactions) goes directly against “best practices” advice from Snowflake, and would almost assuredly result in unwieldy bottlenecks.
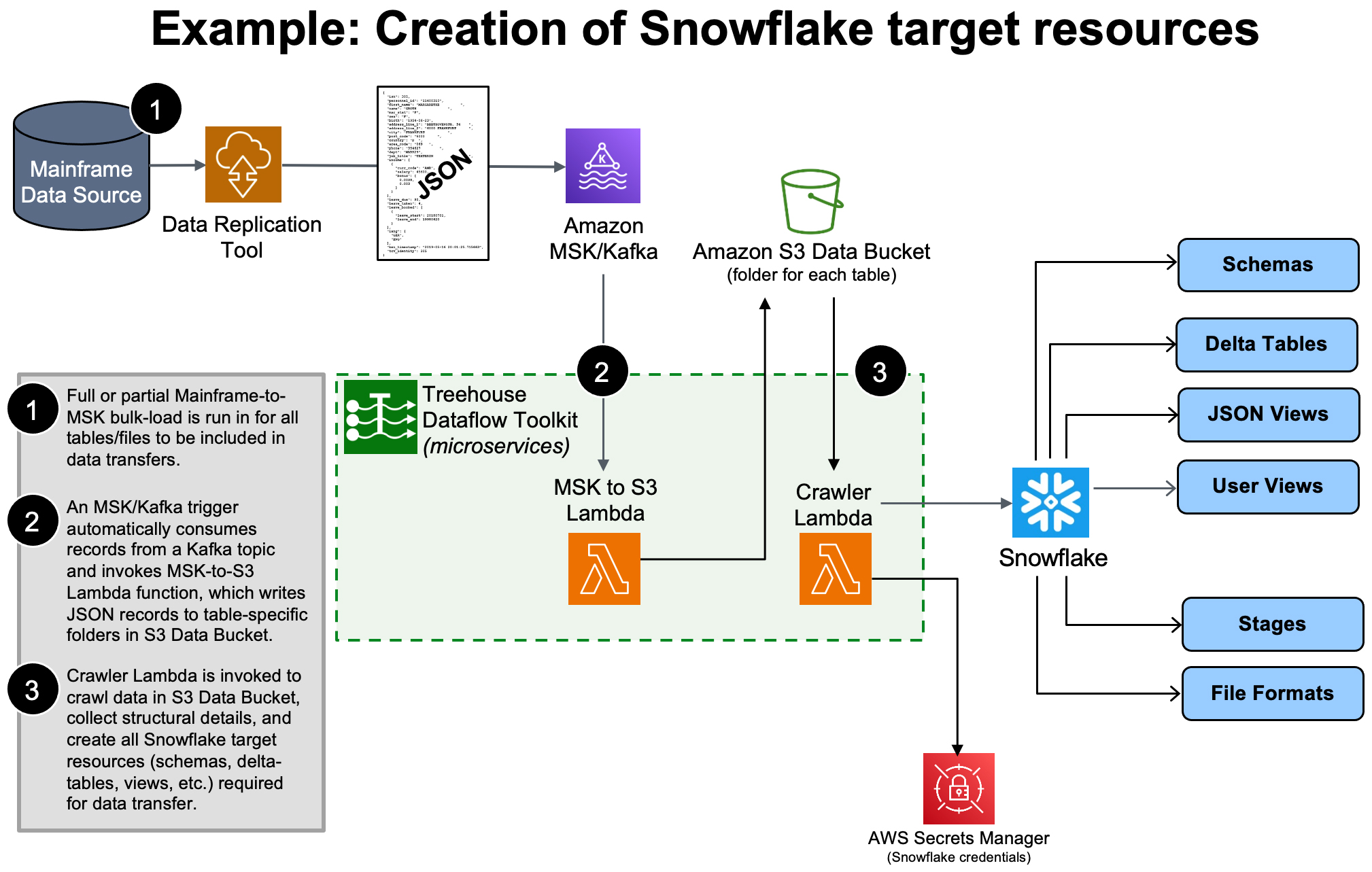
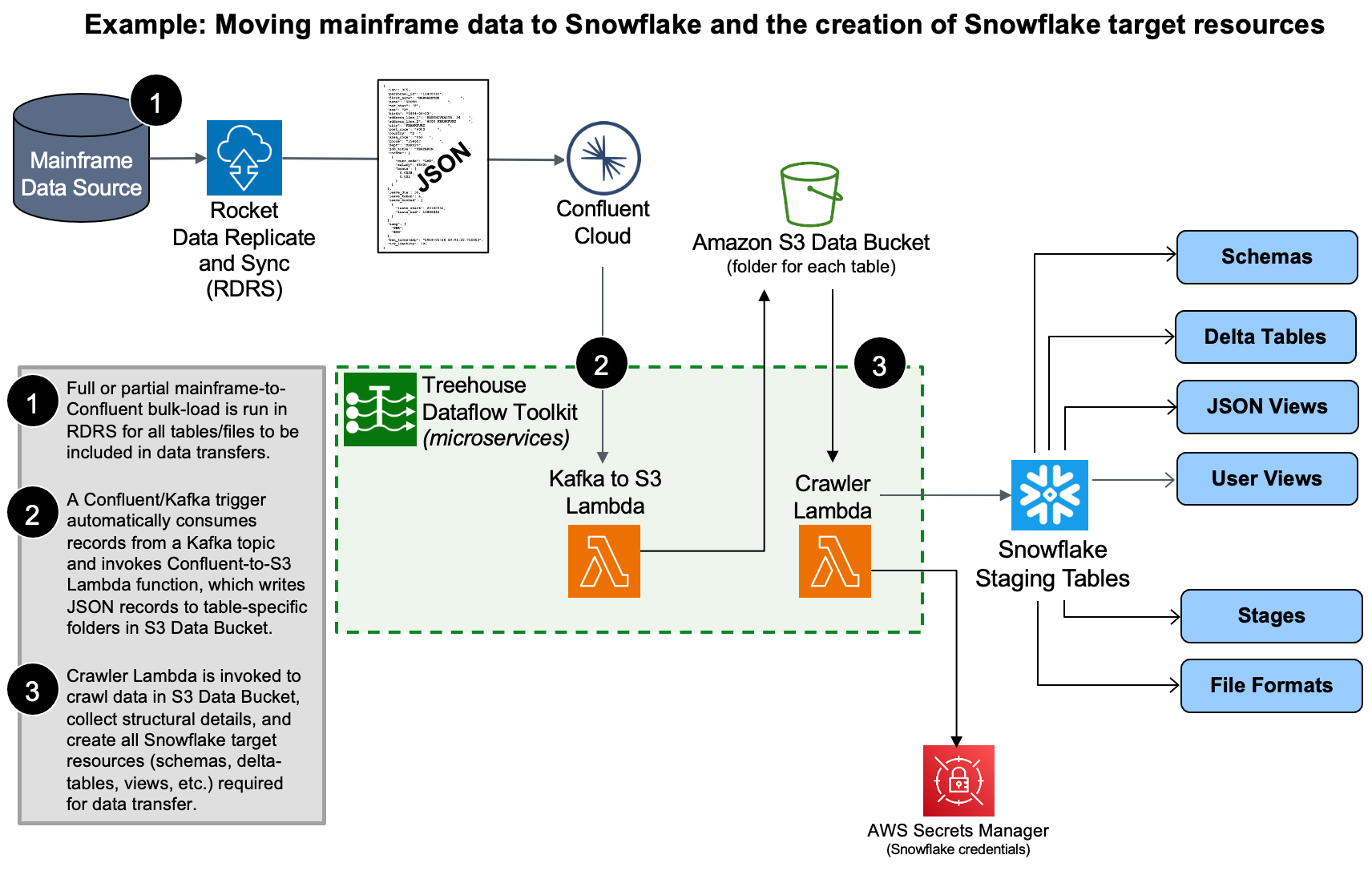
TDT loads data into Snowflake’s “delta tables”, which inherently retain the entire history of source data ever since the source-to-target synchronization began (perfect for time-based trend/predictive/prescriptive analytics). Again, TDT adheres to Snowflake’s best practices recommendation for pulling data from S3 for bulk loading massive quantities of data…
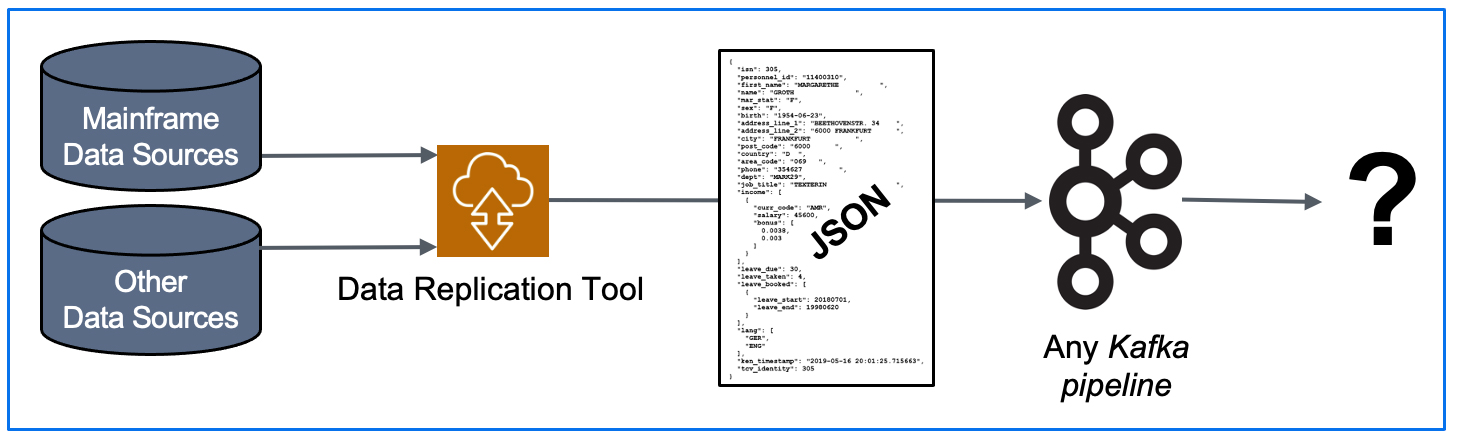
Publishing both bulk-load and CDC data to a reliable and scalable framework like Kafka allows you to maintain a broad array of options to ultimately feed your legacy data to any number of JSON-friendly ETL tools, target data stores, and data analytics packages (some of which have not even been invented yet!).
The “build vs buy” question is put to rest…
The Snowflake-proprietary target DDL/metadata/resources that TDT automatically produces for the staging of data in Snowflake are of such complexity that it is easy to justify the “buy” option in the “build vs buy” conversations customers have. A decision by an enterprise not to use TDT, but instead to build its own Kafka-to-Snowflake solution, could result in any or all of the following:
- accumulation of technical debt
- extensive/unpredictable time to production
- ongoing resource planning to maintain home-grown technologies
- potential vendor lock for maintenance of custom-made technologies designed and developed by consultants
- managing a mix of manual and automated functions
- tracking cobbled together components created by multiple staff and consultants
- limited agility for future customization and innovation
- problems adhering to evolving best practices over time
- higher costs for future growth/scaling
- potential lack of proper security/ongoing security updates
- your organization has now become an enterprise software development company, whether or not you intended that, and whether or not you realized that!
Simply put, TDT is a self-contained, turn-key solution that can eliminate months, or years, of research and development time and costs. With TDT, high-speed and massive data movement to Snowflake takes minutes to ramp up.
Download the TDT AWS Partner Solution Brief to share with your team…

Treehouse Dataflow Toolkit (TDT) is Copyright © 2024 Treehouse Software, Inc. All rights reserved.

Contact Treehouse Software for a Demo Today!
Contact Treehouse Software today for more information or to schedule a product demonstration.


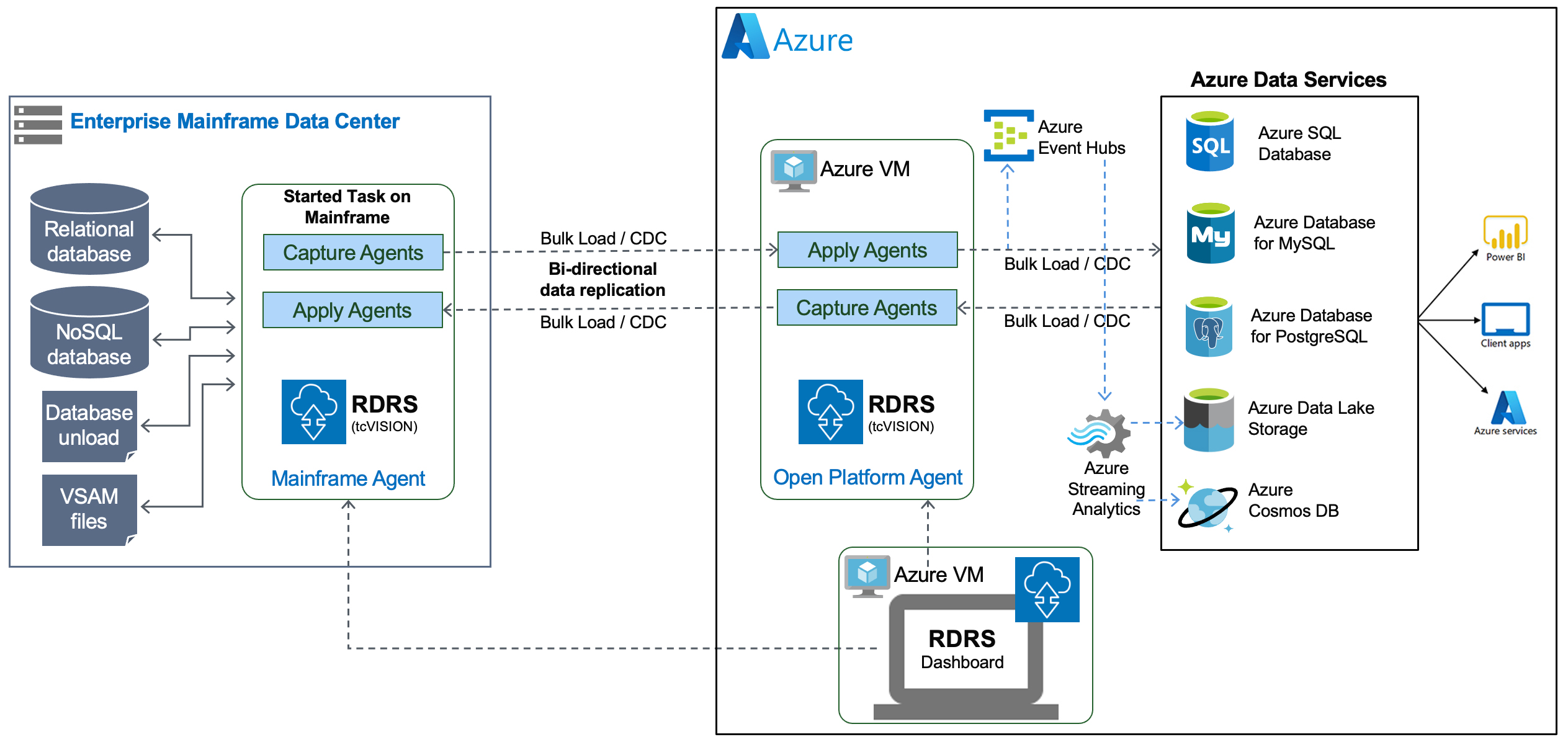

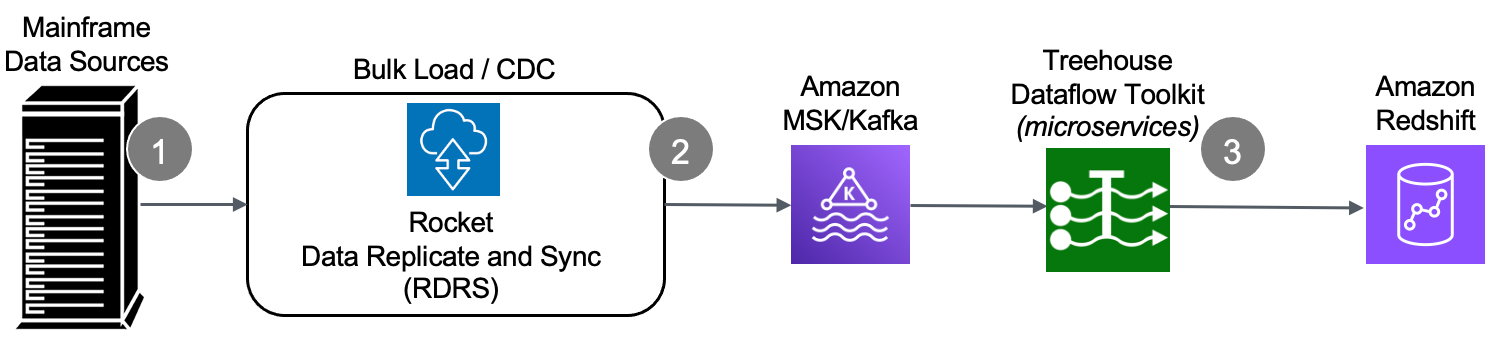 How does it work?
How does it work?