by Joseph Brady, Director of Business Development / Cloud Alliance Leader at Treehouse Software, Inc.

Many Treehouse Software customers have discovered the value of saving weeks, or months in their mainframe modernization initiatives by engaging in a Rocket Data Replicate and Sync (RDRS) Proof of Concept (POC) for Mainframe-to-Cloud data replication. Depending on the complexity of the customer’s project, an RDRS POC generally lasts as little as 10 business days after the product is installed and all connectivity is set up between the mainframe and Cloud environments.
How does it work?
- Treehouse Software provides documentation beforehand that outlines all of the requirements and agenda for the POC, and Treehouse technicians assist in downloading and installing RDRS.
- The customer provides a representative subset of z/OS or z/VSE mainframe data (e.g., Db2, Adabas, VSAM, IMS/DB, CA IDMS, CA DATACOM, etc.), use case, and goals for the POC, and the Treehouse team mentors the customer’s technical team via remote screen sharing sessions.
- The application is executed on customer facilities, in a non-production environment, and a limited-scope implementation of RDRS is conducted to prove that the product meets the customer’s desired use case.
By the end of the POC, customers will have replicated mainframe data on their Cloud target, tested out product capabilities, and demonstrated a successful, repeatable data replication process, with documented results. After the POC, the customer has all the connectivity and processes in place to begin setting up the production phase of their mainframe data modernization project. The minimal cost and resources makes an RDRS POC a valuable ROI in the customer’s mainframe modernization journey.
About RDRS…
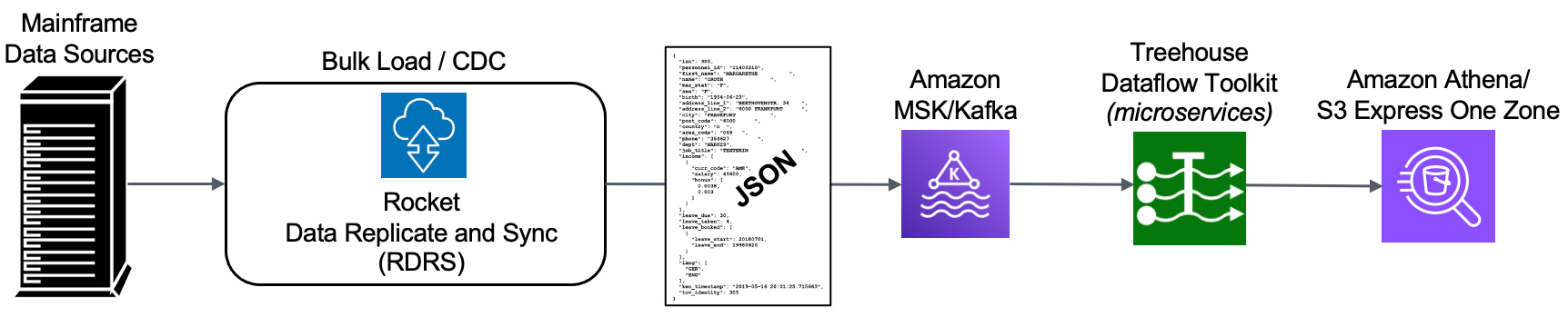
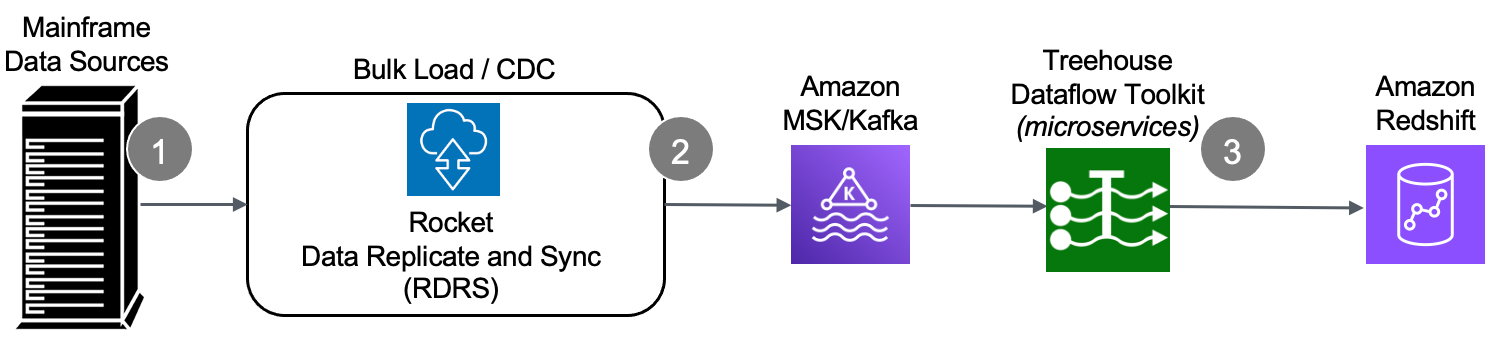
Many Cloud and Systems Integration partners are recommending RDRS for mainframe data modernization projects. RDRS focuses on changed data capture (CDC) when transferring information between mainframe data sources and Cloud targets. Through an innovative technology, changes occurring in any mainframe application data are tracked and captured, and then published to a variety of RDBMS and other targets.
RDRS utilizes a Windows-based GUI Control Board, which is ideal for non-mainframe programmers. While mainframe experts are required in the design/architecture phase during the POC and occasionally during implementation, the requirement for their involvement is limited. The RDRS Control Board acts as a single point of administration, data modeling and mapping, script generation, and monitoring. Comprehensive monitoring and logging of all data movements ensure transparency across all data exchange processes.
Additionally, once RDRS is up and running, the customer’s legacy mainframe environment can continue as long as needed, while they replicate data – in real time and bi-directionally – on the new Cloud platform. Now the enterprise can quickly take advantage of the latest Cloud services, such as advanced analytics, ML/AI, etc., as well as move data to a variety of highly available and secure databases and data stores.
Contact Treehouse Software Today…
Contact us to discuss how a Treehouse Software POC can accelerate your mainframe Cloud and hybrid Cloud data modernization journey.
 How does it work?
How does it work?