by Joseph Brady, Director of Business Development at Treehouse Software, Inc. and Dan Vimont, Director of Innovation at Treehouse Software, Inc.

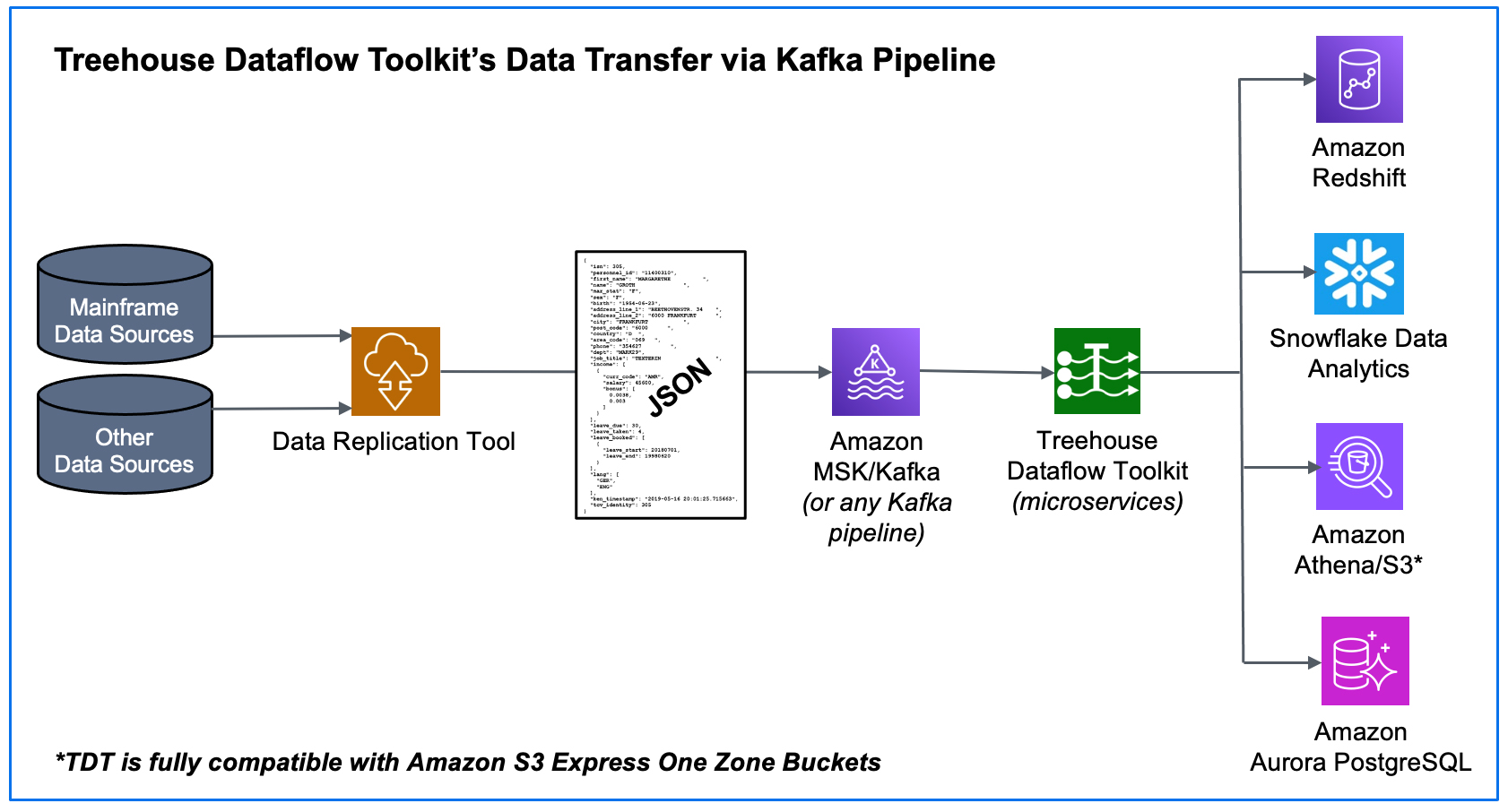
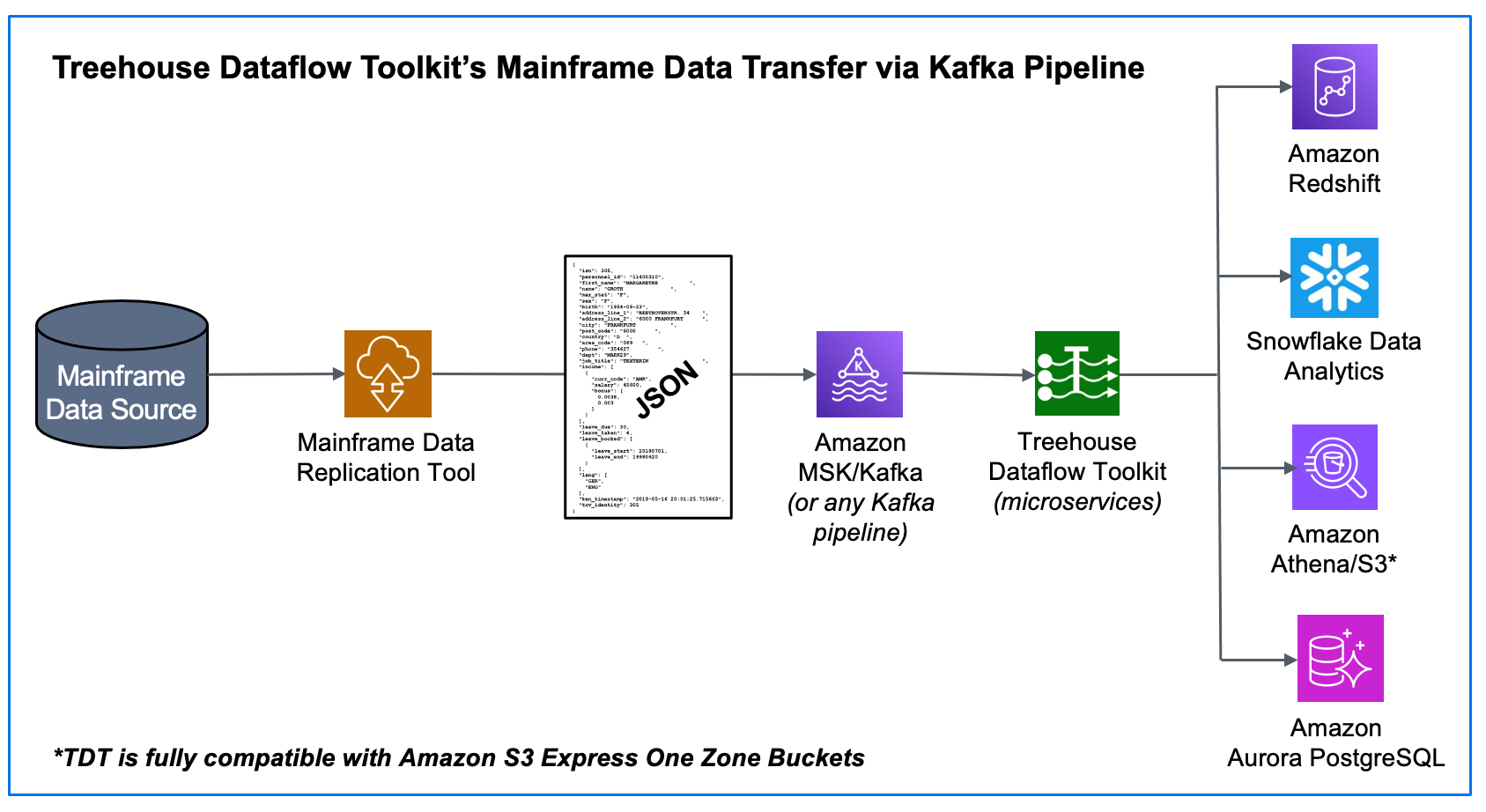
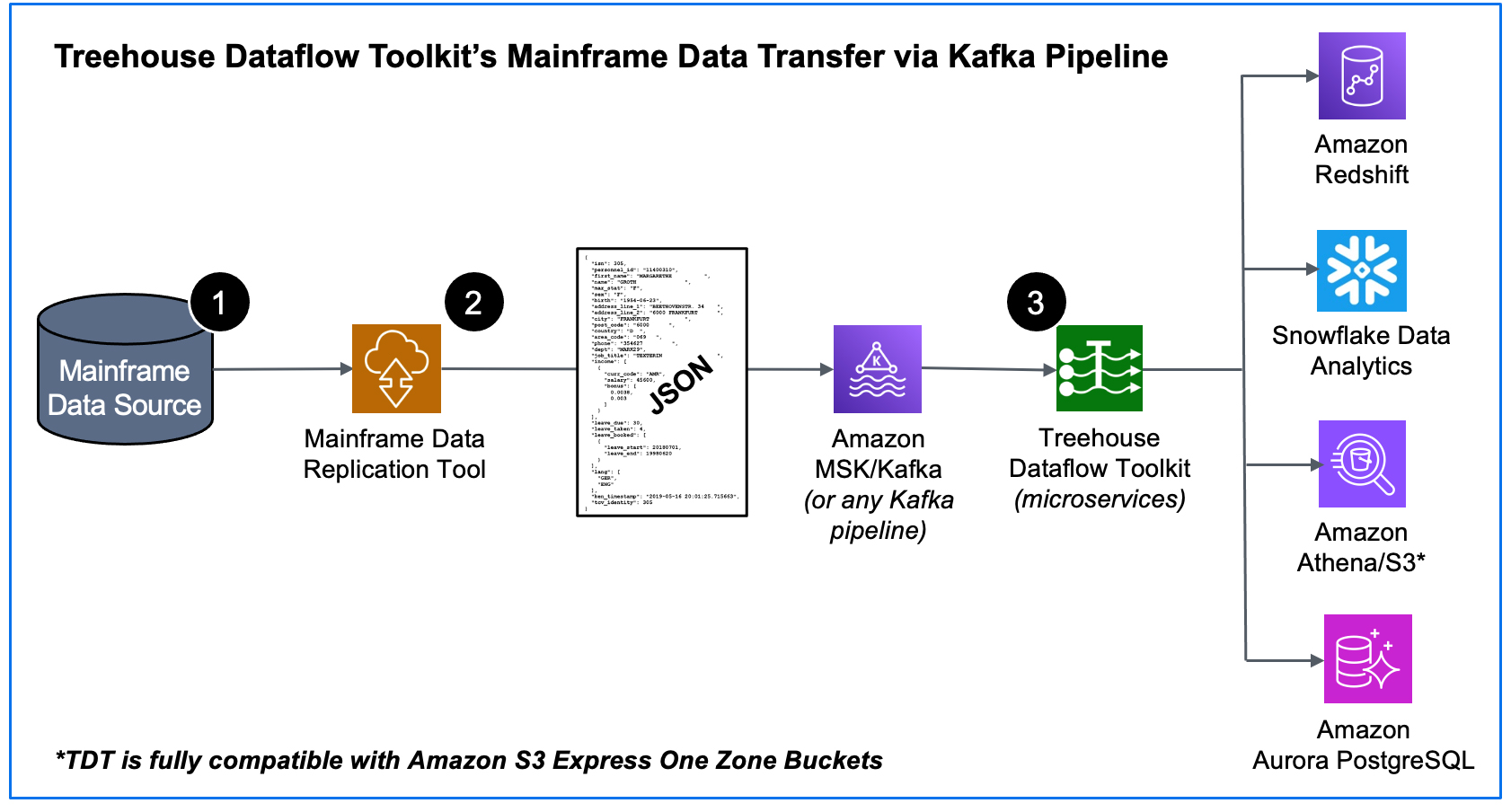
As mentioned in several Treehouse blogs, our innovative offering, Treehouse Dataflow Toolkit (TDT), provides the turn-key solution for rapidly transferring data from Kafka into advanced Analytics/AI/ML-friendly targets, such as Snowflake, Amazon Redshift, Amazon Athena/S3, Amazon S3 Express One Zone Buckets, as well as Amazon Aurora PostgreSQL.
This blog focuses on TDT’s utilization of Amazon RDS Proxy, a brilliantly designed, fully managed, and highly available database proxy for Amazon Relational Database Service (RDS). RDS Proxy is the ultimate “traffic cop” that makes applications more scalable, more resilient to database failures, and more secure.
When TDT targets Amazon PostgreSQL, RDS Proxy auto-maintains a pool of connections to PostgreSQL, which ensures the target does not become overwhelmed during times of massive data flow. Additionally, there is no need to provision or manage any additional infrastructure to begin using RDS Proxy.

Amazon RDS Proxy Use Cases…
Applications that support highly variable workloads may attempt to open a burst of new database connections. RDS Proxy’s connection governance allows customers to gracefully scale applications dealing with unpredictable workloads by efficiently reusing database connections.
-
- In the TDT context, our Lambda-based infrastructure autoscales up and down in alignment with dataflows, and the RDS Proxy responds by brilliantly managing any increased and decreased connection requirements.
Applications that frequently open and close database connections. RDS Proxy allows customers to maintain a pool of database connections to avoid unnecessary stress on database compute and memory for establishing new connections.
-
- As TDT’s autoscaling results in Lambda instances being spun up or shut down, the RDS Proxy maintains stability with its well-managed connection pool.
Applications that can transparently tolerate database failures without needing to write complex failure handling code. RDS Proxy automatically routes traffic to a new database instance while preserving application connections.
-
- Treehouse strongly recommends that customers take advantage of multi-AZ configurations of their RDS databases, which can be fully leveraged by RDS Proxy to assure continuity of service in the event of AZ-specific outages.
Applications that need extra security, including option to enforce IAM based authentication with relational databases. RDS Proxy also enables customers to centrally manage database credentials through AWS Secrets Manager.
-
- This a great feature of RDS Proxy: TDT requires no access whatsoever to database security credentials, instead letting RDS Proxy (in concert with IAM security and AWS Secrets Manager) manage everything to provide state-of-the-art, best practices security for your target database.
VIDEO – Introduction to Amazon RDS Proxy:
Conclusion
TDT is a self-contained, turn-key solution that eliminates months (possibly years) of research and development time and costs, and customers can be up and running in minutes. With TDT, customers are assured of high-speed and massive data movement that strictly adheres to AWS’s recommended use of massively scalable bulk load utilities, as well as Amazon RDS Proxy for the most efficient and secure connectivity. This adherence to AWS’s best practices is one of TDT’s primary differentiators from other “connector” offerings on the market.
Treehouse Dataflow Toolkit (TDT) is Copyright © 2024 Treehouse Software, Inc. All rights reserved.
Download: TDT AWS Partner Solution Brief to share with your team…

Treehouse Dataflow Toolkit (TDT) is Copyright © 2024 Treehouse Software, Inc. All rights reserved.

Contact Treehouse Software for a Demo Today!
Contact Treehouse Software today for more information or to schedule a product demonstration.